
When interacting with folks, robots and chatbots could make errors, violating an individual’s belief in them. After that, folks might begin to think about bots unreliable. Numerous belief restore methods carried out by smartbots can be utilized to mitigate the unfavourable results of those belief breaches. Nonetheless, it’s unclear whether or not such methods can totally restore belief and the way efficient they’re after repeated violations of belief.
Due to this fact, scientists from the College of Michigan determined to conduct a study of robot behavior strategies to be able to restore belief between a bot and an individual. These belief methods had been apologies, denials, explanations, and guarantees of reliability.
An experiment was performed wherein 240 members labored with a robotic as a colleague on a activity wherein the robotic typically made errors. The robotic would violate the participant’s belief after which counsel a particular technique to revive belief. The members had been engaged as group members and the human-robot communication occurred by means of an interactive digital setting developed in Unreal Engine 4.

The digital setting of the members within the experiment to work together with the robotic.
This setting has been modeled to seem like a sensible warehouse setting. Individuals had been seated at a desk with two shows and three buttons. The shows confirmed the group’s present rating, field processing pace, and the serial quantity members wanted to attain the field submitted by their robotic teammate. Every group’s rating elevated by 1 level every time an accurate field was positioned on the conveyor belt and decreased by 1 level every time an incorrect field was positioned there. In circumstances the place the robotic selected the flawed field and the members marked it as an error, an indicator appeared on the display screen exhibiting that this field was incorrect, however no factors had been added or subtracted from the group’s rating.
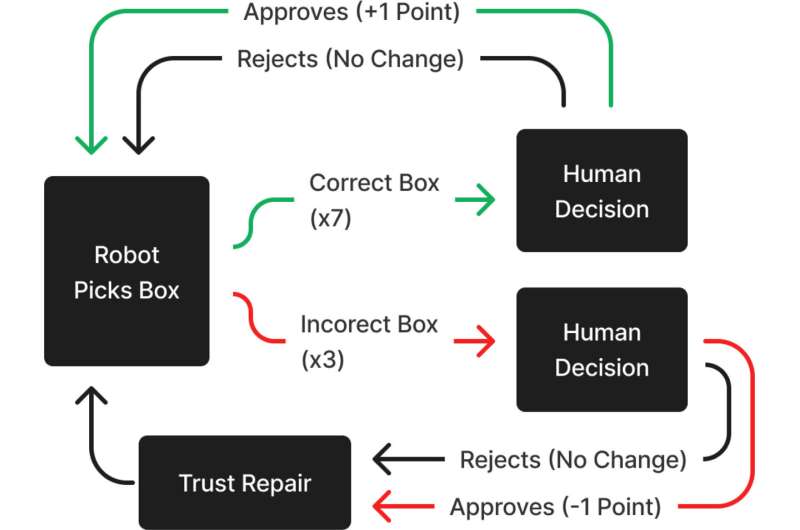
The flowchart illustrates the doable outcomes and scores primarily based on the bins the robotic selects and the choices the participant makes.
“To look at our hypotheses, we used a between-subjects design with 4 restore circumstances and two management circumstances,” stated Connor Esterwood, a researcher on the U-M College of Info and the research’s lead writer.
The management circumstances took the type of robotic silence after making a mistake. The robotic didn’t attempt to restore the individual’s belief in any approach, it merely remained silent. Additionally, within the case of the best work of the robotic with out making errors through the experiment, he additionally didn’t say something.
The restore circumstances used on this research took the type of an apology, a denial, an evidence, or a promise. They had been deployed after every error situation. As an apology, the robotic stated: “I’m sorry I acquired the flawed field that point”. In case of denial, the bot said: “I picked the proper field that point, so one thing else went flawed”. For explanations, the robotic used the phrase: “I see it was the flawed serial quantity”. And at last, for the promise situation, the robotic stated, “Subsequent time, I’ll do higher and take the proper field”.
Every of those solutions was designed to current just one sort of trust-building technique and to keep away from inadvertently combining two or extra methods. In the course of the experiment, members had been knowledgeable of those corrections by means of each audio and textual content captions. Notably, the robotic solely briefly modified its conduct after one of many belief restore methods was delivered, retrieving the proper bins two extra occasions till the subsequent error occurred.
To calculate the info, the researchers used a collection of non-parametric Kruskal–Wallis rank sum assessments. This was adopted by publish hoc Dunn’s assessments of a number of comparisons with a Benjamini–Hochberg correction to manage for a number of speculation testing.
“We chosen these strategies over others as a result of information on this research had been non-normally distributed. The primary of those assessments examined our manipulation of trustworthiness by evaluating variations in trustworthiness between the right efficiency situation and the no-repair situation. The second used three separate Kruskal–Wallis assessments adopted by publish hoc examinations to find out members’ rankings of capacity, benevolence, and integrity throughout restore circumstances,” stated Esterwood and Robert Lionel, Professor of Info and co-author of the research.
The principle outcomes of the research:
- No belief restore technique utterly restored the robotic’s trustworthiness.
- Apologies, explanations and guarantees couldn’t restore the notion of capacity.
- Apologies, explanations and guarantees couldn’t restore the notion of honesty.
- Apologies, explanations, and guarantees restored the robotic’s goodwill in equal measure.
- Denial made it unimaginable to revive the concept of the robotic’s reliability.
- After three failures, not one of the belief restore methods ever totally restored the robotic’s trustworthiness.
The outcomes of the research have two implications. Based on Esterwood, researchers have to develop simpler restoration methods to assist robots rebuild belief after their errors. As well as, bots should ensure that they’ve mastered a brand new activity earlier than making an attempt to revive human belief in them.
“In any other case, they threat dropping an individual’s belief in themselves a lot that will probably be unimaginable to revive it,” concluded Esterwood.