
Introduction
Clustering is an unsupervised machine learning algorithm that teams collectively comparable information factors primarily based on standards like shared attributes. Every cluster has information factors which might be just like the opposite information factors within the cluster whereas as an entire, the cluster is dissimilar to different information factors. By making use of clustering algorithms, we will uncover hidden constructions, patterns, and correlations within the information. Fuzzy C Means (FCM) is one among the many number of clustering algorithms. What makes it stand out as a robust clustering approach is that it may possibly deal with complicated, overlapping clusters. Allow us to perceive this system higher by way of this text.
Studying Aims
- Perceive what Fuzzy C Means is.
- Understand how the Fuzzy C Means algorithm works.
- Have the ability to differentiate between Fuzzy C Means and Okay Means.
- Study to implement Fuzzy C Means utilizing Python.
This text was printed as part of the Data Science Blogathon.
What’s Fuzzy C Means?
Fuzzy C Means is a comfortable clustering approach through which each information level is assigned a cluster together with the chance of it being within the cluster.
However wait! What’s comfortable clustering?
Earlier than entering into Fuzzy C Means, allow us to perceive what comfortable clustering means and the way it’s totally different from arduous clustering.
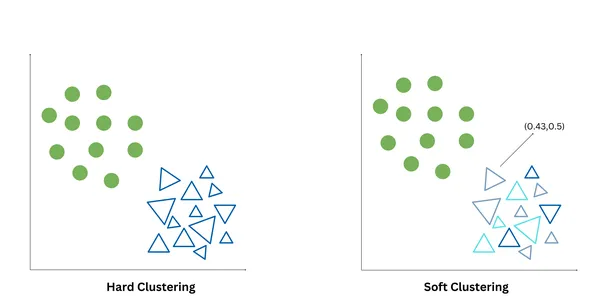
Arduous clustering and comfortable clustering are two other ways to partition information factors into clusters. Arduous clustering, also called crisp clustering, assigns every information level precisely to 1 cluster, primarily based on some standards like for instance – the proximity of the info level to the cluster centroid. It produces non-overlapping clusters. K-Means is an instance of arduous clustering.
Tender clustering, also called fuzzy clustering or probabilistic clustering, assigns every information level a level of membership/chance values that point out the probability of an information level belonging to every cluster. Tender clustering permits the illustration of information factors which will belong to a number of clusters. Fuzzy C Means and Gaussian Mixed Models are examples of Tender clustering.
Working of Fuzzy C Means
Now that we’re clear with the distinction in arduous and comfortable clustering, allow us to perceive the working of the Fuzzy C Means algorithm.
Methods to Run the FCM Algorithm
- Initialization: Randomly select and initialize cluster centroids from the info set and specify a fuzziness parameter (m) to regulate the diploma of fuzziness within the clustering.
- Membership Replace: Calculate the diploma of membership for every information level to every cluster primarily based on its distance to the cluster centroids utilizing a distance metric (ex: Euclidean distance).
- Centroid Replace: Replace the centroid worth and recalculate the cluster centroids primarily based on the up to date membership values.
- Convergence Verify: Repeat steps 2 and three till a specified variety of iterations is reached or the membership values and centroids converge to secure values.
The Maths Behind Fuzzy C Means
In a standard k-means algorithm, we mathematically remedy it through the next steps:
- Randomly initialize the cluster facilities, primarily based on the k-value.
- Calculate the space to every centroid utilizing a distance metric. Ex: Euclidean distance, Manhattan distance.
- Assign the clusters to every information level after which kind k-clusters.
- For every cluster, compute the imply of the info factors belonging to that cluster after which replace the centroid of every cluster.
- Replace till the centroids don’t change or a pre-defined variety of iterations are over.
However in Fuzzy C-Means, the algorithm differs.
1. Our goal is to attenuate the target operate which is as follows:
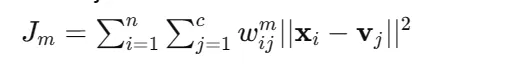
Right here:
n = variety of information level
c = variety of clusters
x = ‘i’ information level
v = centroid of ‘j’ cluster
w = membership worth of information level of i to cluster j
m = fuzziness parameter (m>1)
2. Replace the membership values utilizing the components:
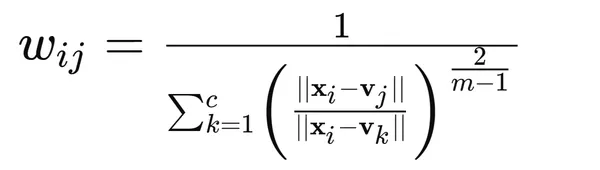
3. Replace cluster centroid values utilizing a weighted common of the info factors:
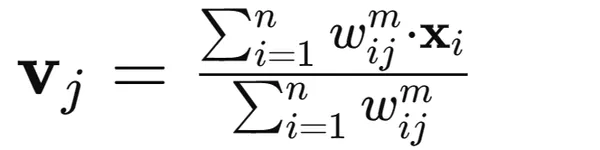
4. Preserve updating the membership values and the cluster facilities till the membership values and cluster facilities cease altering considerably or when a predefined variety of iterations is reached.
5. Assign every information level to the cluster or a number of clusters for which it has the best membership worth.
How is Fuzzy C Means Completely different from Okay-Means?
There are numerous variations in each these clustering algorithms. Just a few of them are:
| Fuzzy C Means | Okay-Means |
| Every information level is assigned a level of membership to every cluster, indicating the chance or probability of the purpose belonging to every cluster. | Every information level is completely assigned to 1 and just one cluster, primarily based on the closest centroid, sometimes decided utilizing Euclidean distance. |
| It doesn’t impose any constraints on the form or variance of clusters. It could deal with clusters of various styles and sizes, making it extra versatile. | It assumes that clusters are spherical and have equal variance. Thus it might not carry out properly with clusters of non-spherical shapes or various sizes. |
| It’s much less delicate to noise and outliers because it permits for comfortable, probabilistic cluster assignments. | It’s delicate to noise and outliers within the information |
Implementation of FCM Utilizing Python
Allow us to now implement Fuzzy C Means utilizing Python.
I’ve downloaded the dataset from the next supply: mall_customers.csv · GitHub
!pip set up scikit-fuzzy
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import skfuzzy as fuzz
from sklearn.preprocessing import StandardScaler
###Load and discover the dataset
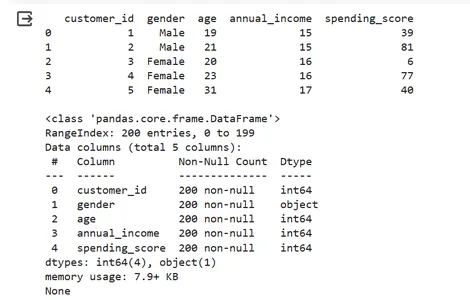
information = pd.read_csv("/content material/mall_customers.csv")
# Show the primary few rows of the dataset and verify for lacking values
print(information.head(),"n")
print(information.information())
# Preprocess the info
X = information[['Annual Income (k$)', 'Spending Score (1-100)']].values
print(X)
# Scale the options
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
print(X_scaled)
#Apply Fuzzy C Means clustering
n_clusters = 5 # Variety of clusters
m = 2 # Fuzziness parameter
cntr, u, u0,d,jm,p, fpc = fuzz.cluster.cmeans(
X_scaled.T, n_clusters, m, error=0.005, maxiter=1000, init=None
)
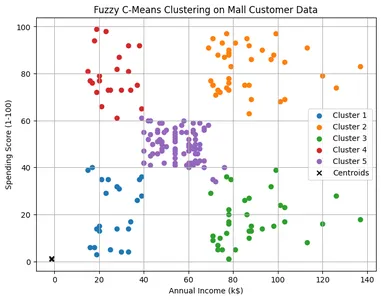
# Visualize the clusters
cluster_membership = np.argmax(u, axis=0)
plt.determine(figsize=(8, 6))
for i in vary(n_clusters):
plt.scatter(X[cluster_membership == i, 0], X[cluster_membership == i, 1], label=f'Cluster {i+1}')
plt.scatter(cntr[0], cntr[1], marker="x", coloration="black", label="Centroids")
plt.title('Fuzzy C-Means Clustering on Mall Buyer Knowledge')
plt.xlabel('Annual Revenue (ok$)')
plt.ylabel('Spending Rating (1-100)')
plt.legend()
plt.grid(True)
plt.present()Right here:
- information: The enter information matrix, the place every row represents an information level and every column represents a function.
- clusters: The variety of clusters to be fashioned.
- m: The fuzziness exponent, which controls the diploma of fuzziness within the clustering.
- error: The termination criterion specifies the minimal change within the partition matrix (u) between consecutive iterations. If the change falls under this threshold, the algorithm terminates.
- maxiter: The utmost variety of iterations allowed for the algorithm to converge. If the algorithm doesn’t converge inside this restrict, it terminates prematurely.
- init: The preliminary cluster facilities. If None, random initialization is used.
The operate returns the next:
- u: The ultimate fuzzy partition matrix, the place every component u[i, j] represents the diploma of membership.
- u0: The preliminary fuzzy partition matrix.
- d: The ultimate distance matrix, the place every component d[i, j] represents the space between the i-th information level and the j-th cluster centroid.
- jm: The target operate worth at every iteration of the algorithm.
- p: The ultimate variety of iterations carried out by the algorithm.
- fpc: The fuzzy partition coefficient (FPC), which measures the standard of the clustering answer.
Output:

Functions of FCM
Listed below are the 5 most typical functions of the FCM algorithm:
- Picture Segmentation: Segmenting photographs into significant areas primarily based on pixel intensities.
- Sample Recognition: Recognizing patterns and constructions in datasets with complicated relationships.
- Medical Imaging: Analyzing medical photographs to determine areas of curiosity or anomalies.
- Buyer Segmentation: Segmenting prospects primarily based on their buying conduct.
- Bioinformatics: Clustering gene expression information to determine co-expressed genes with comparable capabilities.
Benefits and Disadvantages of FCM
Now, let’s focus on the benefits and downsides of utilizing Fuzzy C Means.
Benefits
- Robustness to Noise: FCM is much less delicate to outliers and noise in comparison with conventional clustering algorithms.
- Tender Assignments: Supplies comfortable, probabilistic assignments.
- Flexibility: Can accommodate overlapping clusters and ranging levels of cluster membership.
Limitations
- Sensitivity to Initializations: Efficiency is delicate to the preliminary placement of cluster centroids.
- Computational Complexity: The iterative nature of FCM can improve computational expense, particularly for big datasets.
- Number of Parameters: Selecting applicable values for parameters such because the fuzziness parameter (m) can affect the standard of the clustering outcomes.
Conclusion
Fuzzy C Means is a clustering algorithm that could be very various and fairly highly effective in uncovering hidden meanings (within the type of patterns) in information, providing flexibility in dealing with complicated datasets. It may be thought-about a greater algorithm in comparison with the k-means algorithm. By understanding its ideas, functions, benefits, and limitations, information scientists and practitioners can leverage this clustering algorithm successfully to extract invaluable insights from their information, making well-informed selections.
Key Takeaways
- Fuzzy C Means is a comfortable clustering approach permitting for probabilistic cluster assignments, contrasting with the unique assignments of arduous clustering algorithms like Okay-Means.
- It iteratively updates cluster membership and centroids, minimizing an goal operate to realize convergence and uncover complicated, overlapping clusters.
- Not like Okay-Means, FCM is much less delicate to noise and outliers because of its probabilistic strategy, making it appropriate for datasets with diverse constructions.
- Python implementation of FCM utilizing libraries like scikit-fuzzy permits practitioners to use this system effectively to real-world datasets, facilitating information evaluation and decision-making.
Incessantly Requested Questions
A. Fuzzy C Means is a clustering algorithm that goals to enhance the prevailing Okay-Means algorithm by permitting comfortable assignments of clusters to information factors, primarily based on the diploma of membership/chance values in order that information factors can belong to a number of clusters.
A. Jim Bezdek developed the overall case in 1973 for any m>1. He developed this in his PhD thesis at Cornell College. Joe Dunn first reported the FCM algorithm in 1974 for a particular case (m=2).
A. Fuzziness parameter controls the diploma of fuzziness or uncertainty in cluster assignments. For instance: if m=1, then the info level will belong solely to 1 cluster. Whereas, if m=2, then the info level has a level of membership equal to 0.8 for one cluster, and a membership worth equal to 0.2 for an additional cluster. This means that there’s a excessive likelihood of the info level belonging to cluster 1 whereas additionally an opportunity of it belonging to cluster 2.
A. They’re up to date iteratively by performing a weighted common of the info factors the place the weights are the membership values of every information level.
A. Sure! Among the fuzzy clustering algorithms aside from FCM are the Gustafson-Kessel algorithm and the Gath-Geva algorithm.
The media proven on this article on Knowledge Visualization Instruments aren’t owned by Analytics Vidhya and is used on the Writer’s discretion.