Introduction
In natural language processing (NLP), it is extremely necessary understand and efficiently course of sequential data. Prolonged Temporary-Time interval Memory (LSTM) fashions have emerged as a sturdy software program for tackling this downside. They supply the potential to grab every short-term nuances and long-term dependencies inside sequences. Sooner than delving into the intricacies of LSTM language translation fashions, it’s important to grasp the fundamental concept of LSTMs and their place inside Recurrent Neural Networks (RNNs). This textual content presents a whole data to understanding, implementing, and evaluating LSTM fashions for language translation duties, with a give consideration to translating English sentences into Hindi. By way of a step-by-step technique, we’ll uncover the architecture, preprocessing strategies, model establishing, teaching, and evaluation of LSTM fashions.
Learning Objective
- Understand the fundamentals of LSTM construction.
- Study to preprocess sequential data for LSTM fashions.
- Implement LSTM fashions for sequence prediction duties.
- Think about and interpret LSTM model effectivity.
What’s RNN?
Recurrent Neural Networks (RNNs) serve a significant aim throughout the area of neural networks attributable to their distinctive means to cope with sequential data efficiently. Not like completely different types of neural networks, RNNs are significantly designed to grab dependencies inside sequential data components.
Take into consideration the occasion of textual content material data, the place each data degree Xi represents a sequence of phrases or sentences. In pure language, the order of phrases points significantly, along with the semantic relationships between them. However, commonplace neural networks usually overlook this side, treating the enter as an unordered set of choices. Consequently, they wrestle to grasp the inherent development and which means contained in the textual content material.
RNNs deal with this limitation by sustaining relationships between phrases all through the whole sequence. They acquire this by introducing a time axis, primarily making a looped development the place each phrase throughout the enter sequence is processed sequentially, incorporating information from every the current phrase and the context supplied by earlier phrases.
This development permits RNNs to grab short-term dependencies contained in the data. However, they nonetheless face challenges in preserving long-term dependencies efficiently. Inside the context of the time axis illustration, RNNs encounter downside in sustaining strong connections between the first and last phrases of the sequence. That’s primarily because of tendency for earlier inputs to have a lot much less have an effect on on later predictions, ensuing within the potential lack of context and which means over longer sequences.
What’s LSTM?
Sooner than delving into LSTM language translation fashions, it’s necessary to grasp the concept of LSTMs.
LSTM stands for Prolonged Temporary-Time interval Memory, which is a specialised type of RNN. As a result of the title suggests, LSTMs are designed to efficiently seize every long-term and short-term dependencies inside sequential data. For many who’re interested by finding out additional about RNNs and LSTMs, you presumably can uncover the belongings on the market here and here. Nonetheless let me offer you a concise overview of them.
LSTMs gained recognition for his or her means to deal with the constraints of standard RNNs, considerably in sustaining every long-term and short-term dependencies inside sequential data. This achievement is facilitated by the distinctive development of LSTMs.
The LSTM development would possibly initially appear intricate, nevertheless I’ll simplify it for increased understanding. The time axis of an data degree, labeled as xt0 to xtn, corresponds to explicit particular person blocks representing cell states, denoted as h_t, which output the corresponding cell state. The yellow sq. bins characterize activation options, whereas the spherical pink bins signify pointwise operations. Let’s delve into the core concept.
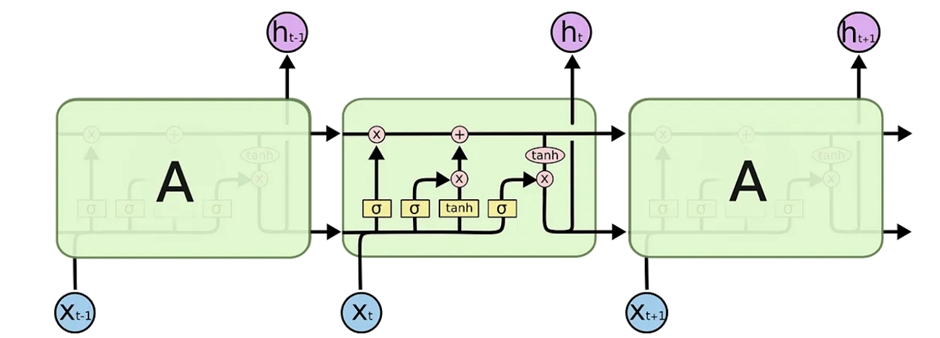
The fundamental idea behind LSTMs is to deal with long-term and short-term dependencies efficiently. That’s achieved by selectively discarding unimportant elements x_t whereas retaining essential ones by means of id mapping. LSTMs could possibly be distilled into three main gates, each serving a particular aim.
1. Neglect Gate
The Neglect Gate determines the relevance of knowledge from the sooner state to be retained or discarded for the next state. It merges information from the sooner hidden state h_t-1 and the current enter x_t, passing it by means of a sigmoid function to offer values between 0 and 1. Values nearer to 0 signify information to miss, whereas these nearer to 1 level out information to take care of, achieved by means of acceptable weight backpropagation all through teaching.
2. Enter Gate
The Enter Gate manages data updates to the cell state. It merges and processes the sooner hidden state h_t-1 and the current enter x_t by means of a sigmoid function, producing values between 0 and 1. These values, indicating significance, are pointwise multiplied with the output of the tanh function, which squashes values between -1 and 1 to handle the group. The following product determines the associated information to be added to the cell state.
3. Cell State
The Cell State combines the quite a few information retained from the Neglect Gate (representing the important information from the sooner state) and the Enter Gate (representing the important information from the current state) by means of pointwise addition. This change yields a model new cell state c_t that the neural network deems associated.
4. Output Gate
Lastly, the Output Gate determines the data associated to the next hidden state. It merges the sooner hidden state and the current enter proper right into a sigmoid function to seek out out which information to retain. Concurrently, the modified cell state is handed by means of a tanh function. The outputs are then multiplied to resolve the data to carry forward to the next hidden state.
It’s important to note that the hidden state retains information from earlier enter states, making it useful for predictions, and is handed as a result of the output for the current state h_t.
Downside Assertion
Our aim is to benefit from an LSTM sequence-to-sequence model to translate English sentences into their corresponding Hindi counterparts.
For this, I am taking a dataset from hugging face
Step 1: Loading the Information from Hugging Face
!pip arrange datasets
from datasets import load_datasetdf=load_dataset("Aarif1430/english-to-hindi")
df['train'][0]

import pandas as pd
da = pd.DataFrame(df['train']) # Assuming you could load the apply break up
da.rename(columns={'english_sentence': 'english', 'hindi_sentence': 'hindi'}, inplace=True)
da.head()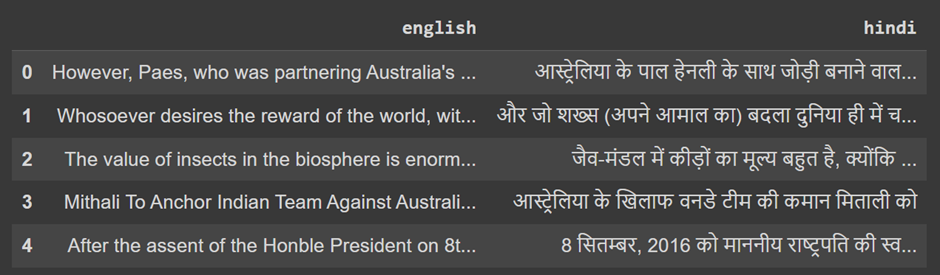
On this code, we arrange the dataset library if not already put in. Then, use the load_dataset function to load the English-Hindi dataset from Hugging Face. We convert the dataset into pandas DataFrame for extra processing and present the first few rows to substantiate the data loading.
Step 2: Importing Wanted Libraries
import numpy as np
import string
from numpy import array, argmax, random, take
import pandas as pd
from keras.fashions import Sequential
from keras.layers import Dense, LSTM, Embedding, RepeatVector
from keras.preprocessing.textual content material import Tokenizer
from keras.callbacks import ModelCheckpoint
from keras.preprocessing.sequence import pad_sequences
from keras.fashions import load_model
from keras import optimizers
from tensorflow.keras.fashions import Sequential
from tensorflow.keras.layers import Embedding, LSTM
import matplotlib.pyplot as plt
import tensorflow as tf
import warnings
warnings.filterwarnings("ignore")Proper right here, we now have imported all of the required libraries and modules required for data preprocessing, model establishing, and evaluation.
Step 3: Information Preprocessing
#Eradicating punctuations and altering textual content material to lowercase for every languages
da['english'] = da['english'].str.substitute('[{}]'.format(string.punctuation), '').str.lower()
da['hindi'] = da['hindi'].str.substitute('[{}]'.format(string.punctuation), '').str.lower()# Uncover indices of empty rows in every languages
eng_empty_indices = da[da['english'].str.strip().astype(bool) == False].index
hin_empty_indices = da[da['hindi'].str.strip().astype(bool) == False].index
# Combine indices from every languages to remove empty rows
remove_indices = guidelines(set(eng_empty_indices) | set(hin_empty_indices))
# Eradicating empty rows
da.drop(remove_indices, inplace=True)
# Reset indices
da.reset_index(drop=True, inplace=True)
Proper right here , we preprocess the data by eradicating punctuation and altering textual content material to lowercase for every English and Hindi sentences. Furthermore, we cope with empty rows by discovering and eradicating them from the dataset.
Step 4: Tokenization and Sequence Padding
# Importing compulsory libraries
from tensorflow.keras.preprocessing.textual content material import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences# Initialize Tokenizer for English subtitles
tokenizer_eng = Tokenizer()
tokenizer_eng.fit_on_texts(da['english'])
# Convert textual content material to sequences of integers for English subtitles
sequences_eng = tokenizer_eng.texts_to_sequences(da['english'])
# Initialize Tokenizer for Hindi subtitles
tokenizer_hin = Tokenizer()
tokenizer_hin.fit_on_texts(da['hindi'])
# Convert textual content material to sequences of integers for Hindi subtitles
sequences_hin = tokenizer_hin.texts_to_sequences(da['hindi'])
# Pad sequences to ensure uniform measurement
max_length = 100 # Define the utmost sequence measurement
sequences_eng = pad_sequences(sequences_eng, maxlen=max_length, padding='submit')
sequences_hin = pad_sequences(sequences_hin, maxlen=max_length, padding='submit')
# Affirm the vocabulary sizes
vocab_size_eng = len(tokenizer_eng.word_index) + 1
vocab_size_hin = len(tokenizer_hin.word_index) + 1
print("Vocabulary measurement for English subtitles:", vocab_size_eng)
print("Vocabulary measurement for Hindi subtitles:", vocab_size_hin)

Proper right here, we import the required libraries for tokenization and sequence padding. Then, we tokenize the textual content material data for every English and Hindi sentences and convert them into sequences of integers. We pad the sequences to ensure uniform measurement, and finally, we print the vocabulary sizes for every languages.
Determining Sequence Lengths
eng_length = sequences_eng.type[1] # Measurement of English sequences
hin_length = sequences_hin.type[1] # Measurement of Hindi sequences
print(eng_length, hin_length)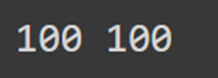
On this, we’re determining the lengths of the sequences for every English and Hindi sentences. The scale of a sequence refers again to the number of tokens or phrases throughout the sequence.
Step 5: Splitting Information into Teaching and Validation Items
from sklearn.model_selection import train_test_split# Break up the teaching data into teaching and validation items
X_train, X_val, y_train, y_val = train_test_split(sequences_eng[:50000], sequences_hin[:50000], test_size=0.2, random_state=42)
# Affirm the shapes of the datasets
print("Type of X_train:", X_train.type)
print("Type of y_train:", y_train.type)
print("Type of X_val:", X_val.type)
print("Type of y_val:", y_val.type)
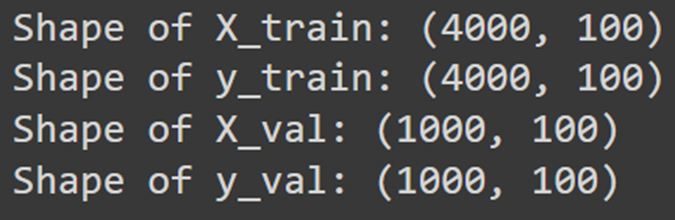
On this step, we’re splitting the preprocessed data into teaching and validation items.
Step 6: Establishing The LSTM Model
from keras.fashions import Sequential
from keras.layers import Dense, LSTM, Embedding, RepeatVectormodel = Sequential()
model.add(Embedding(input_dim=vocab_size_eng, output_dim=128,input_shape=(eng_length,), mask_zero=True))
model.add(LSTM(fashions=512))
model.add(RepeatVector(n=hin_length))
model.add(LSTM(fashions=512, return_sequences=True))
model.add(Dense(fashions=vocab_size_hin, activation='softmax'))
This step entails establishing the LSTM sequence-to-sequence model for English to Hindi translation. Let’s break down the layers added to the model:
The first layer is an embedding layer (Embedding) which maps each phrase index to a dense vector illustration. It takes as enter the vocabulary measurement for English (vocab_size_eng), the output dimensionality (output_dim=128), and the enter type specified by the utmost sequence measurement for English (input_shape=(eng_length,)). Furthermore, mask_zero=True is about to ignore padded zeros.
Subsequent, we add an LSTM layer (LSTM) with 512 fashions, which processes the embedded sequences.
The RepeatVector layer repeats the output of the LSTM layer for hin_length cases, preparing it to be fed into the next LSTM layer.
Then, we add one different LSTM layer with 512 fashions, set to return sequences (return_sequences=True), which is crucial for sequence-to-sequence fashions.
Lastly, we add a dense layer (Dense) with a softmax activation function to predict the chance distribution over the Hindi vocabulary for each time step.
Printing the Model Summary
model.summary()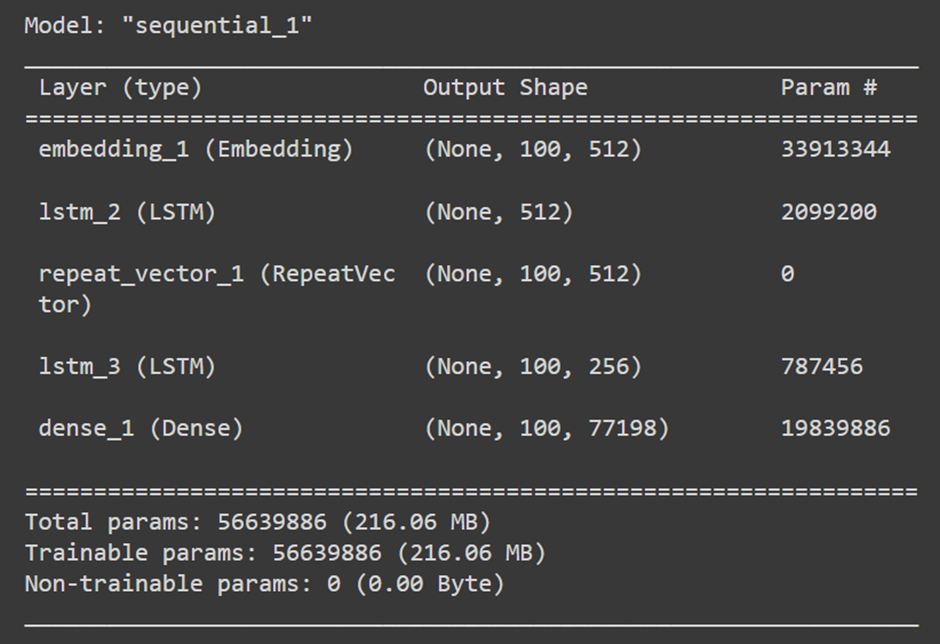
Step 7: Compiling and Teaching the Model
from tensorflow.keras.optimizers import RMSprop# Define optimizer
rms = RMSprop(learning_rate=0.001)
# Compile the model
model.compile(optimizer=rms, loss="sparse_categorical_crossentropy", metrics=['accuracy'])
# Put together the model
historic previous = model.match(X_train, y_train, validation_data=(X_val, y_val), epochs=10, batch_size=32)
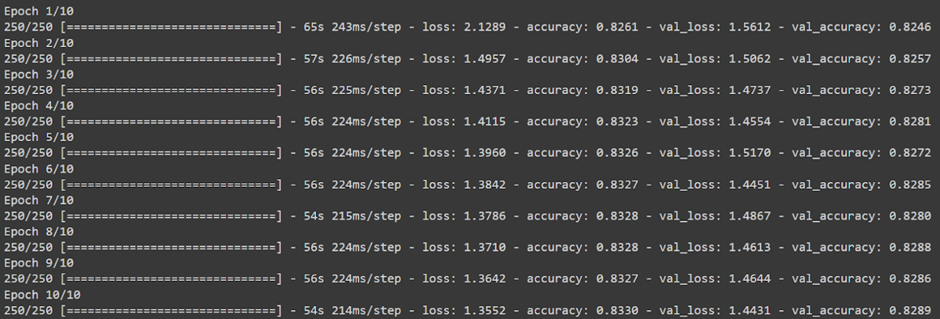
This step compiles the LSTM model with rms optimizer, sparse_categorical_crossentropy loss function, and accuracy metrics. Then, it trains the model on the supplied data for 10 epochs, using a batch measurement of 32. The teaching course of yields a historic previous object capturing teaching metrics over epochs.
Step 8: Plotting Teaching and Validation Loss
import matplotlib.pyplot as plt# Get the teaching historic previous
loss = historic previous.historic previous['loss']
val_loss = historic previous.historic previous['val_loss']
epochs = fluctuate(1, len(loss) + 1)
# Plot loss and validation loss with custom-made colors
plt.plot(epochs, loss, 'r', label="Teaching Loss") # Pink color for teaching loss
plt.plot(epochs, val_loss, 'g', label="Validation Loss") # Inexperienced color for validation loss
plt.title('Teaching and Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.current()
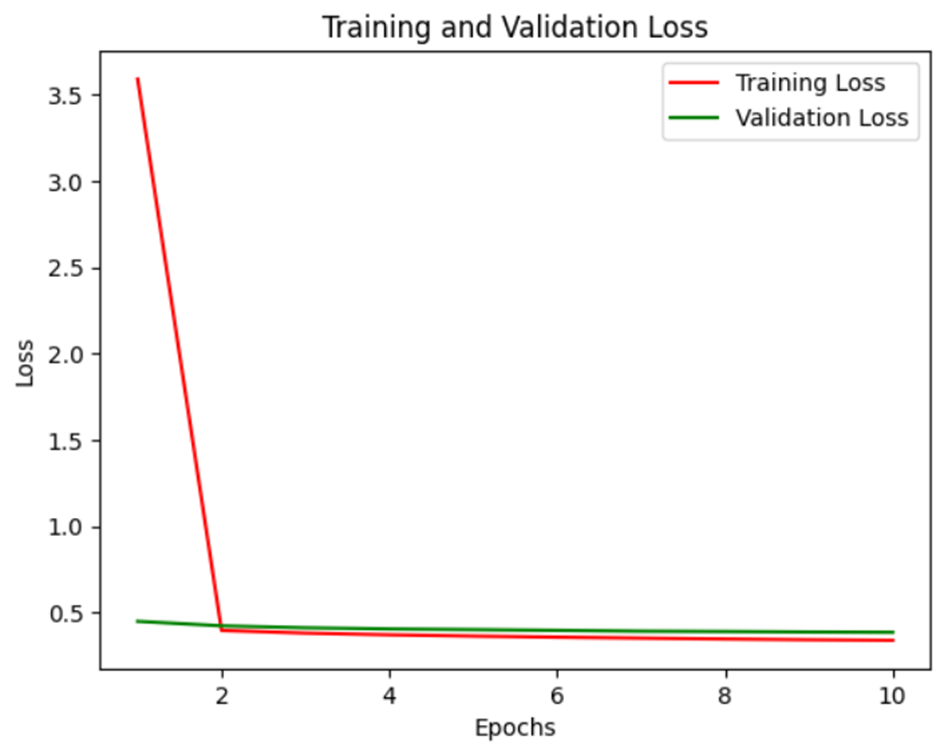
This step entails plotting the teaching and validation loss over epochs to visualise the model’s finding out progress and potential overfitting.
Conclusion
This data navigates the creation of an LSTM sequence-to-sequence model for English-to-Hindi language translation. It begins with a top level view of RNNs and LSTMs, emphasizing their means to cope with sequential data efficiently. The goal is to translate English sentences into Hindi using this model.
Steps embrace data loading from Hugging Face, preprocessing to remove punctuation and cope with empty rows, and tokenization with sequence padding for uniform measurement. The LSTM model is meticulously constructed with embedding, LSTM, RepeatVector, and dense layers. Teaching entails compiling the model with an optimizer, loss function, and metrics, adopted by changing into it to the dataset over epochs.
Visualizing teaching and validation loss supplies insights into the model’s finding out progress. Ultimately, this data empowers clients with the skills to assemble LSTM fashions for language translation duties, providing a foundation for extra exploration in NLP.
Steadily Requested Questions
A. An LSTM (Prolonged Temporary-Time interval Memory) sequence-to-sequence model is a type of neural group construction designed to translate sequences of knowledge from one language to a special. It makes use of LSTM fashions to grab every short-term and long-term dependencies inside sequential data efficiently.
A. The LSTM model processes enter sequences, typically in English, and generates corresponding output sequences, typically in a single different language like Hindi. It does so by finding out to encode the enter sequence proper right into a fixed-size vector illustration after which decoding this illustration into the output sequence.
A. Preprocessing steps embrace eradicating punctuation, coping with empty rows, tokenizing the textual content material into sequences of integers, and padding the sequences to ensure uniform measurement.
A. Widespread evaluation metrics embrace teaching and validation loss, which measure the discrepancy between predicted and exact sequences all through teaching. Furthermore, metrics like BLEU score may be utilized to guage the model’s effectivity.
A. Effectivity could possibly be improved by experimenting with utterly completely different model architectures, adjusting hyperparameters much like finding out worth and batch measurement, rising the size of the teaching dataset, and utilizing strategies like consideration mechanisms to offer consideration to associated elements of the enter sequence all through translation.
A. Positive, the LSTM model could possibly be tailor-made to translate between pairs of languages apart from English and Hindi. By teaching the model on datasets containing sequences in quite a few languages, it could be taught to hold out translation duties for these language pairs as correctly.