
One of many key discoveries within the newest part of AI, is the flexibility to seek for and discover paperwork based mostly on similarity search.
Similarity search is an method that compares data based mostly on its that means reasonably than by way of key phrases.
Similarity search is also referred to as semantic search. The phrase semantic refers back to the “that means or interpretation of phrases, phrases or symbols inside a selected context.” With semantic search a person can ask a query reminiscent of “What’s the film the place the protagonist climbs by way of 500 ft of fowl smelling s*&t?” and the AI will reply with “The Shawshank Redemption”. Performing this sort of search is not possible with key phrase looking.
Semantic search opens up all kinds of potentialities, whether or not for researches looking for particular data out of college collections, or giving builders entry to specific data when querying API documentation.
The genius of semantic search is we are able to convert complete paperwork and pages of textual content right into a illustration of its that means.
The aim of this text is to offer the basics of semantic search, and the fundamental arithmetic behind it. With a deep understanding, you’ll be able to make the most of this new know-how to ship extremely helpful instruments to customers.
The important thing to this know-how is arithmetic of vectors.
You could recall from highschool of college the idea of vectors. The are used reguarly in physics. In physics a vector is outlined as a magnitude plus a course. For instance the automobile is travelling 50 km/hr north.
A vector may be represented graphically:

Vectors have a unique that means in Synthetic Intelligence which we’ll come to shortly. I’ll speak you thru how we get from a vector in Physics to a vector in AI.
Going again to our graphical illustration, if we had been to plot this in a graph we are able to characterize a vector in 2-dimensions.

The top of the vector may be represented by its values on the x-axis and y-axis. This vector may be represented by the purpose [4, 3].
With this level we are able to use trigonometry to calculate it’s magnitude and course.
If we create a vector in 3-dimensions we want three values to characterize that vector in area.

This vector is represented by the purpose [2, 3, 5]. Once more we are able to apply trigonometry to calculate the magnitude and course.
One of many fascinating calculations we are able to carry out with vectors in 2 or 3 dimensions is to find out the similarity between vectors.
In Physics one of many calculations we have to carry out is vector similarity (that is resulting in AI similarity search). For instance within the examine of supplies science, vectors can be utilized to match stress or pressure vectors inside supplies beneath load.
Within the diagram if we had stress vectors that had been comparable we might see that the pressure on the fabric is in the identical course. Whereas reverse forces would apply a specific stress to the fabric.
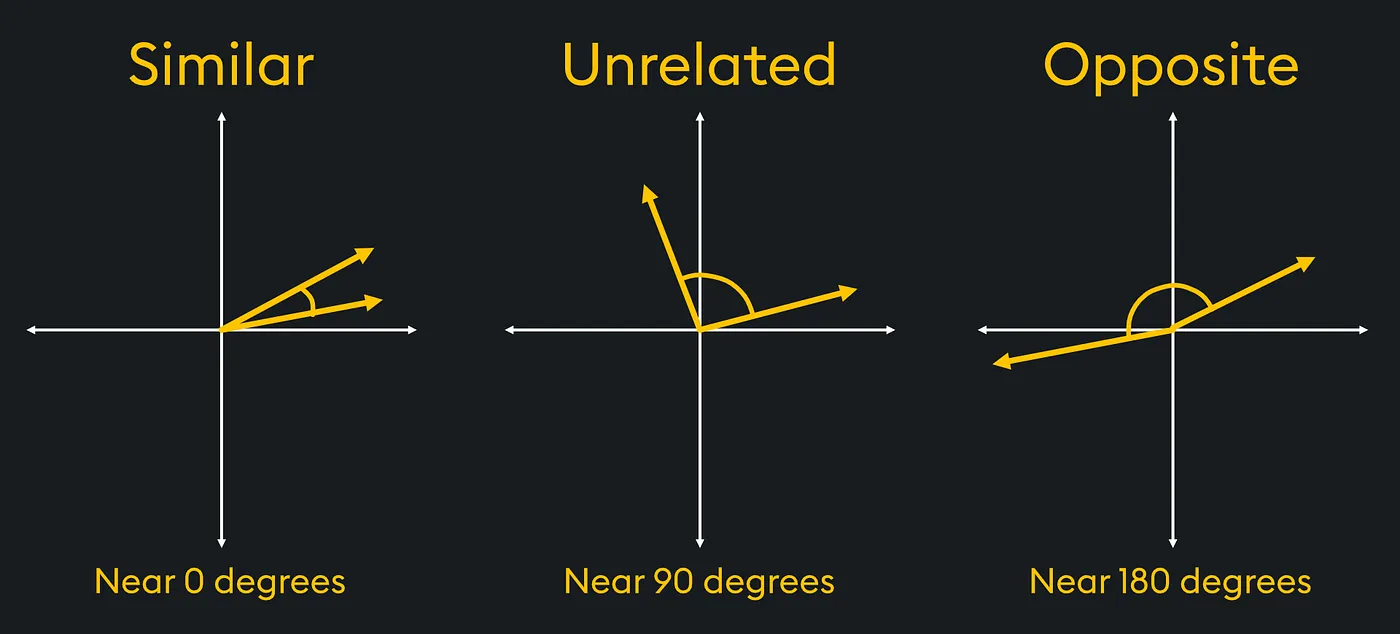
Utilizing trigonometry we might decide which vectors are probably the most comparable or disimilar.
What needs to be famous is {that a} vector may be represented by an array of values. For 3 dimensions a vector is described by three factors, [1, 3, 4].
In Synthetic Intelligence we used arrays to characterize totally different data in a set of knowledge. For instance if we had been utilizing Machine Studying to foretell housing costs we might characterize the entire data in an array.
Let’s have a look at a quite simple instance the place we solely have three information factors to characterize every home. Every factor of the array would characterize a unique characteristic of the home. For instance:
- Worth: A greenback worth.
- Variety of bedrooms: Integer worth.
- Dimension: Measured in sq. ft.
A hypothetical home can be represented as:
Home: [300000, 3, 400]
Utilizing our third-dimensional housing information, we are able to now create an algorithm to making a housing suggestion engine. Listed here are three homes represented by arrays of knowledge:
Home 1: [300000, 3, 400]
Home 2: [320000, 3, 410]
Home 3: [900000, 4, 630]
Plotting these three homes in three dimensions offers us the next graph.
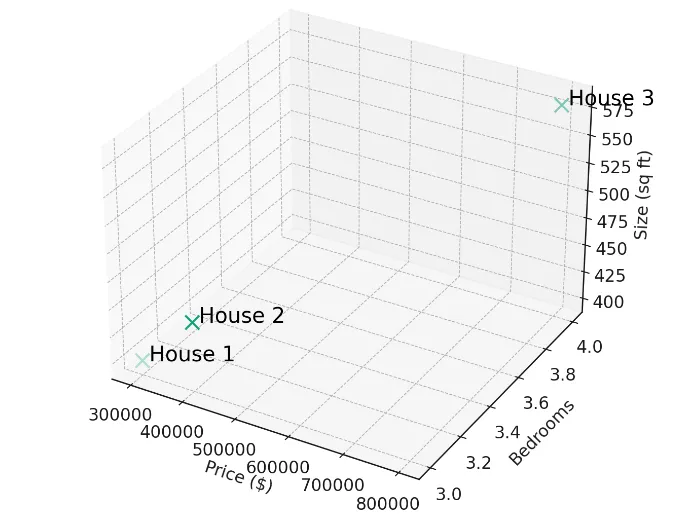
If the person wished to seek out homes most just like home 1 it may shortly be decided that home 2 is probably the most comparable and the advice engine can return the main points of this property to the person.
In Machine Studying the home array is known as a vector. What makes vectors so fascinating is identical arithmetic which are used on Physics vectors applies to arrays of numbers. Therefore, we use the time period vector.
The place it turns into not possible to visualise is when the vector comprises greater than three information factors. A home vector might include many information factors, reminiscent of location, high quality rating, age, variety of loos and so on. A whole home vector might appear like this:
[300000, 3, 400, 122.2, 83.4, 87, 43, 3]
This is named a higher-dimensional vector. On this context a dimension refers to 1 characteristic of the info. The worth is a dimension. The dimensions is one other dimension and so it. Greater-dimensional vectors can’t be represented in third-dimensional area, nevertheless, the identical ideas and arithmetic applies. We will nonetheless run our suggestion engine by discovering the higher-dimensional vectors which are most comparable.
The place issues begin to get actually enjoyable for us, is after we begin to convert textual content into vectors. The genius of contemporary synthetic intelligence is the flexibility to transform phrases, phrases and even pages of textual content right into a vector that represents the that means of that data.
Let’s begin with a single phrase, “Cat”.
Specialised AI fashions can take the phrase cat and switch it right into a vector. This vector is a illustration of the that means of the phrase cat because it pertains to different phrases in its coaching information. These specialised AIs use pre-trained fashions which have discovered characterize textual content as high-dimensional vectors. These vectors seize semantic meanings and relationships between textual content based mostly on their utilization inside their educated information.
Changing textual content into vectors is named Vector Embedding.
“Cat” is perhaps represented by a 300-dimensional vector.
[ 0.49671415, -0.1382643 , 0.64768854, 1.52302986, -0.23415337, -0.23413696, 1.57921282, …]
“Canine” alternatively is perhaps represented by the vector:
[ 1.69052570, -0.46593737, 0.03282016, 0.40751628, -0.78892303, 0.00206557, -0.00089039, …]
If we had been to scale back the Cat and Canine vectors into 2-dimensions it would appear like this.
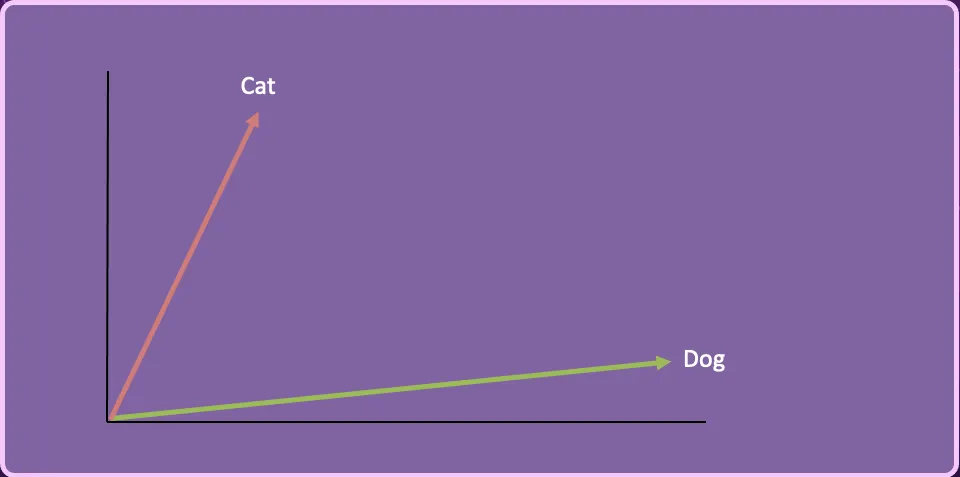
We will take a 3rd phrase “Kitten”, create the vector embedding and characterize it on this 2-dimensional area.
Kitten vector: [-0.05196425, -0.11119605, 1.0417968, -1.25673929, 0.74538768, -1.71105376, -0.20586438, …]
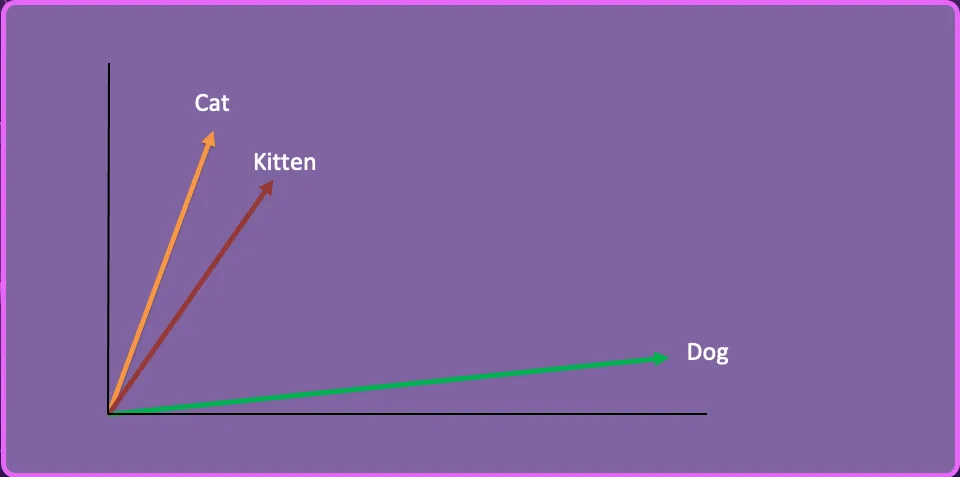
Let’s say now we have a group of articles on feeding cats and canines, and our person asks the next query:
How do I feed my kitten?
By utilizing similarity search, the AI determines that kitten is nearer semantically to Cat than Canine and subsequently returns the articles on feed Cats.
And that is the elemental foundation of similarity/semantic search. By changing textual content into vector embeddings now we have a way to find out the semantic similarity to different data.
One other instance is perhaps to take the abstract of a library of books and convert these into vector embeddings. The graph under exhibits books catelogued by style. You will note that the books are inclined to cluster into teams.
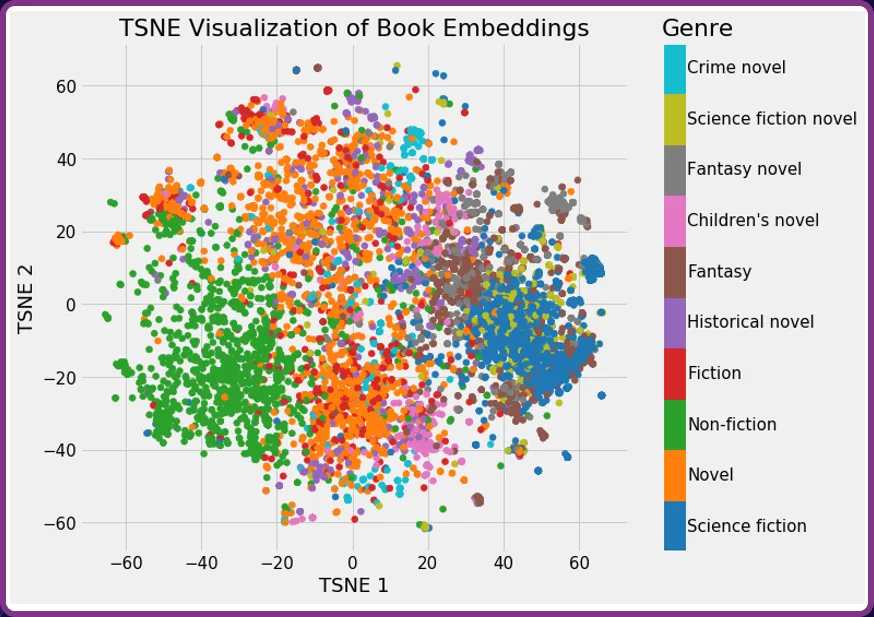
If a person had been searching for suggestions on books just like Dune, it will see Dune clustered inside the ‘Science fiction’ style and return suggestions reminiscent of ‘2001: An area odyssey’.
Vector embeddings are created by specialised AI fashions. OpenAI has their text-embedding-ada-002 mannequin.
With a easy API name, textual content may be handed to the mannequin which can generate a vector embedding. An OpenAI vector embedding is often between 1500 and 3500 parts relying on the particular mannequin used.
For data on utilizing the OpenAI embedding endpoint take a look at: https://platform.openai.com/docs/guides/embeddings
Anthropic with its Claude fashions additionally gives vector embeddings of 1024 parts: https://docs.anthropic.com/claude/docs/embeddings
From a programming perspective, every embedding AI mannequin will return the vector as an array which makes it simple to work with.
Creating Vector embeddings is just an API name away.
Vector embeddings may be saved in any kind of knowledge retailer. I’ve used CSV information throughout early testing (although positively not really helpful for any critical utility).
There are nevertheless specialised Vector databases which have begun to emerge over the previous few years. They’re totally different from conventional databases in that they’re optimised for dealing with vectors. These databases present mechanisms to effectively compute the similarity between these high-dimensional vectors.
Let’s have a look at what the schema of a vector database might appear like. Say we’re operating a Fintech firm with entry to hundreds of economic statements and we wish to have the ability to use AI to question these paperwork.

This vector database has three fields:
- doc_name: The title of the doc.
- doc_url: The place the unique supply doc is saved.
- doc_vector: The vector embedding of the PDF doc.
Virtually each main database administration system has launched a model of a vector database.
PostgreSQL: They’ve launched an extension name pgvector https://www.postgresql.org/about/news/pgvector-050-released-2700/
Redis: Vector Search
https://redis.io/solutions/vector-search/
MongoDB: Atlas vector search
https://www.mongodb.com/products/platform/atlas-vector-search
Pinecone: A specialised vector databse
https://www.pinecone.io/
The selection of vector database actually comes all the way down to your improvement preferences.
Vector databases are optimised for similarity search. There are a number of totally different mathematical approaches, the most typical and easiest to implement is to make use of cosine similarity.
Cosine similarity is a trigonometric measure used to find out how comparable two vectors are. The maths determines the cosine of the angle between the 2 vectors. The cosine of a small angle is near 1, and the cosine of a 90-degree angle is 0. Vectors which are very comparable may have a cosine near 1.

It’s pointless to cowl the arithmetic of calculating cosine similarity, until you’re a maths geek like me wherein case this video explains it very well: https://www.youtube.com/watch?v=e9U0QAFbfLI
The primary take away is the nearer the similarity rating is to 1, the extra comparable the vectors.
Vector databases present features for performing cosine similarity, the place you’ll be able to set parameters such because the variety of outcomes to return. For instance it’s your decision the three closest outcomes.
Performing similarity search requires a number of steps.
- Changing the supply paperwork into vector embeddings and storing these within the vector database.
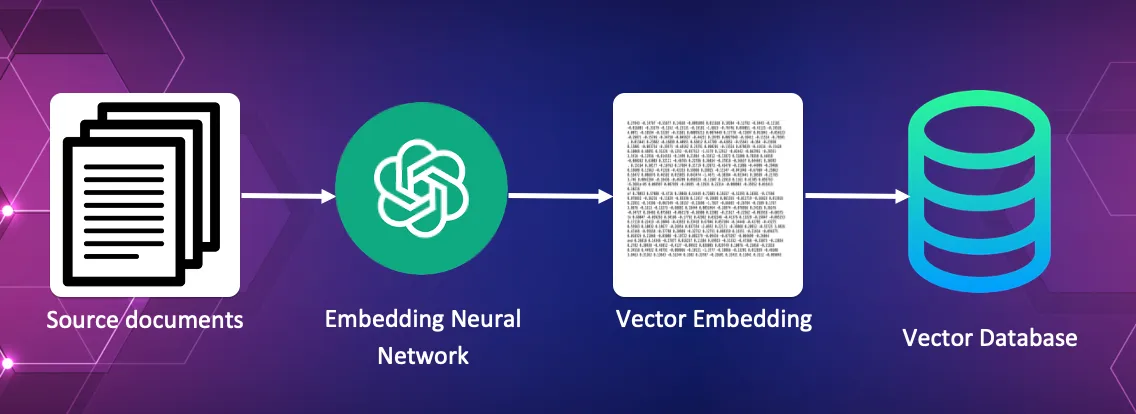
On this course of every supply doc is feed to the embedding AI, which creates the vector embedding. These vector embeddings are then saved inside the vector database together with a reference to the unique supply doc.
For a library this is perhaps a group of newspaper articles from the final 100 years.
2. Changing the question right into a vector and utilizing cosine similarity to seek out the doc most just like the question.
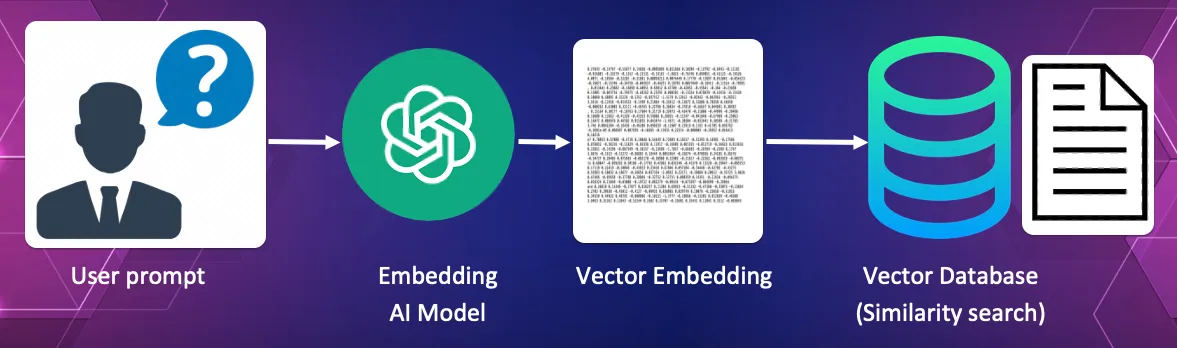
On this course of the customers question itself is transformed right into a vector. This vector is used because the search vector inside the vector database to seek out the doc which greatest solutions the question.
For our library the question is perhaps “I’m searching for a newspaper article in regards to the 1950 Chinchaga fireplace.”
This question is itself transformed right into a vector and handed to the vector database which makes use of its similarity search to seek out the newspaper article with probably the most comparable that means to the question. We might want to return the simply the highest consequence.
The vector database will return the title of the article and the URL to the precise supply textual content.
3. Ship the question together with the supply doc to a LLM to confirm the request.
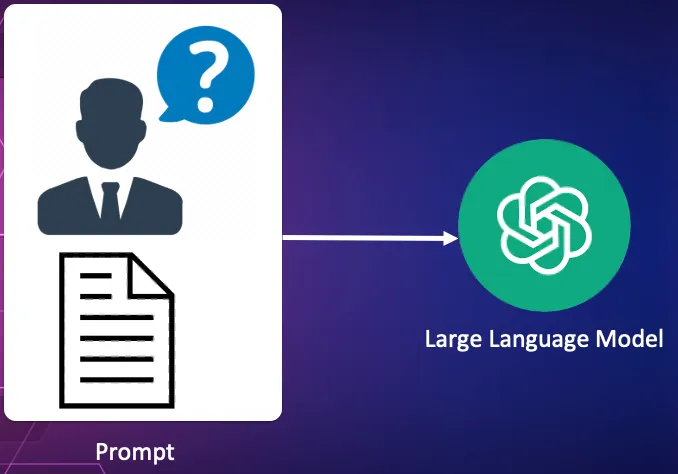
That is the ultimate piece of the puzzle. The question together with the unique supply textual content is shipped to a big language mannequin to course of the question towards the doc. The LLM used could possibly be Claude, OpenAI, Gemini or any of the open-source fashions reminiscent of Llama or Mistral.
In our library instance it will test that the supply doc truly contained details about the Chinchaga fireplace. If that’s the case the person can be supplied with the URL to the supply doc.
This complete course of is named information retrieval or Retrieval Augmented Era (RAG).
Think about you’re working with a API for a bank card cost supplier. As a substitute of getting to trawl by way of API endpoints and documentation, you might simply ask “What’s the endpoint to course of a cost?”.
The AI would used similarity search to seek out the proper doc, and ship your query and the doc to an LLM. The LLM would offer a solution to the query based mostly on the knowledge within the supply doc.
You can then question additional and say “How do I make this API name in Ruby?” Or JavaScript, Python, C++ and so on. The LLM ought to be capable to generate the code, based mostly on the endpoints supply documentation.
Data retrieval is a really highly effective means to enhance the flexibility of customers to achieve entry to and get solutions to their exect questions with out spending time reviewing the improper informaiton.
Data retrieval can be utilized in lots of method. It may be used to seek out and return complete articles to a person. It could possibly discover very particular data inside a big supply of paperwork. It may be used for suggestions. The use instances of data retrieval simply comes all the way down to your creativeness.
Many platforms are starting to launch information retrieval companies, which takes the complexity and improvement work out of the method.
For instance AWS has their Amazon Q service. Amazon Q successfully gives a degree and click on interface to offer it together with your supply paperwork and it’ll construct a information service for you. The great thing about Amazon Q is you may give it precise paperwork, retailer them in S3, or give it a URL and it’ll scrape a complete web site for you. You can too have it mechanically sync the info, so modifications to your paperwork are chosen inside Amazon.
As we progress we’ll start to see a plethora of those companies.
You could have very particular use instances, the place you have to to code your information retrieval from the bottom up. In that case you have to to work with the next instruments:
- Embedding AI
- Vector database
In any other case, your solely limitation is your improvement ability and creativeness.
Data retrieval and similarity search, I imagine, is the entry level to firms profitable AI implementations. The place previously key phrase search was successfully necessary for all web site, we’ll quickly see information retrieval is the minimal customary. I already get annoyed once I attempt to work by way of API docs that don’t have information search.
I look ahead to see the brand new and wonderful concepts you provide you with utilising information retrieval and similarity search.