
Historically, the strategies of coaching options for deep studying (DL) have their roots within the rules of the human mind. On this context, neurons are represented as nodes linked to one another, and the energy of those connections modifications as neurons work together. Deep neural networks include three or extra layers of nodes, together with enter and output layers. Nevertheless, these two studying situations are considerably totally different. Firstly, efficient DL architectures require dozens of hidden feedforward layers, that are presently increasing to a whole bunch, whereas the mind’s dynamics include only a few feedforward layers.
Secondly, deep studying architectures usually embody many hidden layers, with nearly all of them being convolutional layers. These convolutional layers seek for particular patterns or symmetries in small sections of enter information. Then, when these operations are repeated in subsequent hidden layers, they assist establish bigger options that outline the category of enter information. Comparable processes have been noticed in our visible cortex, however approximated convolutional connections have been primarily confirmed from the retinal enter to the primary hidden layer.
One other complicated side of deep studying is that the backpropagation method, which is essential for the operation of neural networks, has no organic analogue. This technique adjusts the weights of neurons in order that they change into extra appropriate for fixing the duty. Throughout coaching, we offer the community with information enter and evaluate how a lot it deviates from what we’d anticipate. We use an error perform to measure this distinction.
Then we start to replace the weights of neurons to cut back this error. To do that, we contemplate every path between the enter and output of the community and decide how every weight on this path contributes to the general error. We use this info to appropriate the weights.
Convolutional and absolutely linked layers of the community play an important function on this course of, and they’re significantly environment friendly as a consequence of parallel computations on graphics processing items. Nevertheless, it’s value noting that such a way has no analogs in biology and differs from how the human mind processes info.
So, whereas deep studying is highly effective and efficient, it’s an algorithm developed solely for machine studying and doesn’t mimic the organic studying course of.
Researchers at Bar-Ilan College in Israel questioned if it is attainable to develop a extra environment friendly type of synthetic intelligence by using an structure resembling a synthetic tree. On this structure, every weight has just one path to the output unit. Their speculation is that such an method might result in larger accuracy in classification than in additional complicated deep studying architectures that use extra layers and filters. The examine is revealed within the journal Scientific Reports.
The core of this examine explores whether or not studying inside a tree-like structure, impressed by dendritic timber, can attain outcomes as profitable as these usually achieved utilizing extra structured architectures involving a number of absolutely linked and convolutional layers.
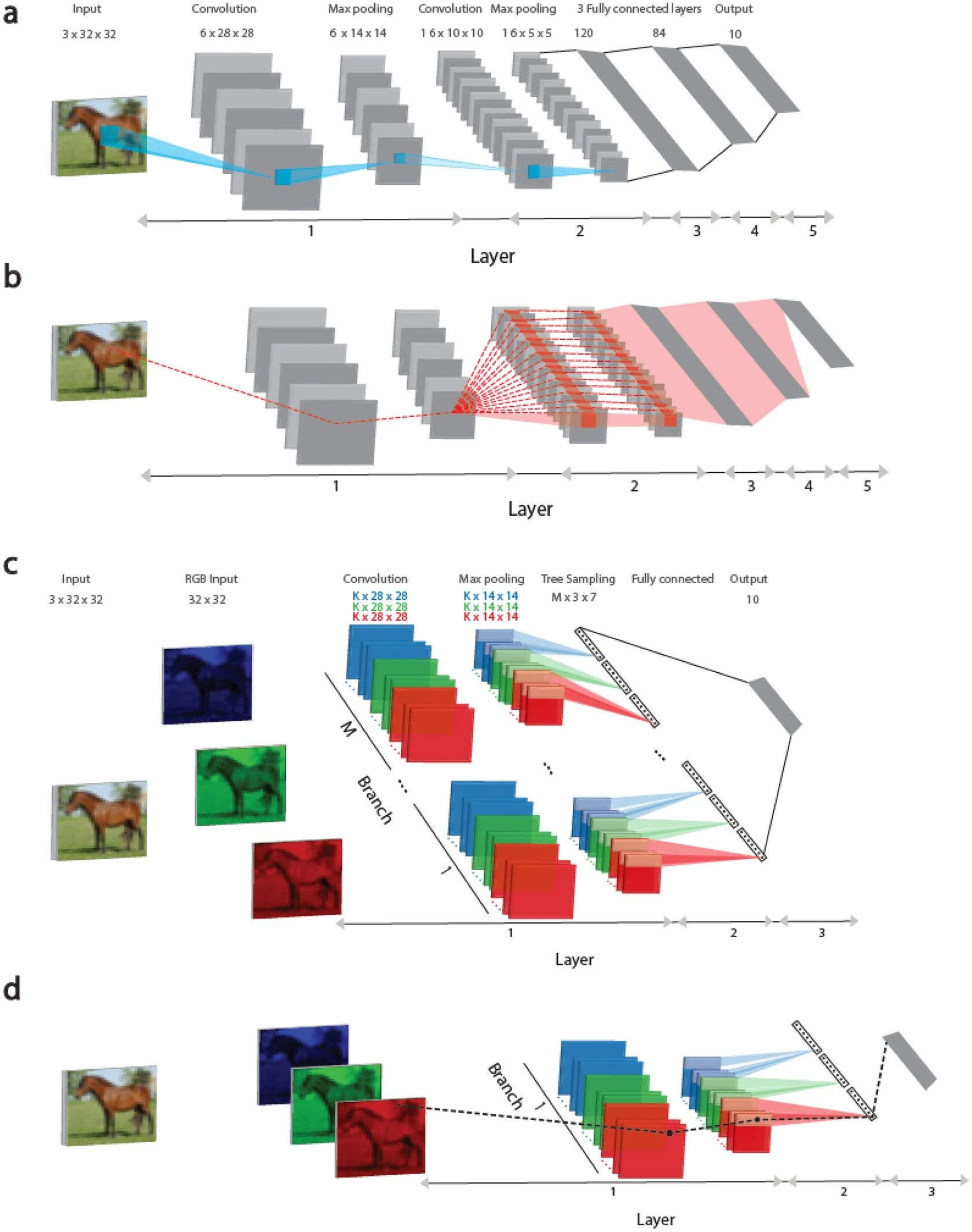
Determine 1
This examine presents a studying method primarily based on tree-like architectures, the place every weight is linked to the output unit by just one route, as proven in Determine 1 (c, d). This method represents a step nearer to implementing organic studying realistically, contemplating recent findings that dendrites (components of neurons) and their quick branches can change, enhancing the energy and expressiveness of indicators passing via them.
Right here, it’s demonstrated that the efficiency metrics of the proposed Tree-3 structure, which has solely three hidden layers, outperform the achievable success charges of LeNet-5 on the CIFAR-10 database.
In Determine 1 (a), the convolutional architectures of LeNet-5 and Tree-3 are thought of. The LeNet-5 convolutional community for the CIFAR-10 database consists of RGB enter pictures sized 32 × 32, belonging to 10 output labels. The primary layer consists of six (5 × 5) convolutional filters, adopted by (2 × 2) max-pooling. The second layer consists of 16 (5 × 5) convolutional filters, and layers 3–5 have three absolutely linked hidden layers of sizes 400, 120, and 84, that are linked to 10 output items.
In Determine 1 (b), the dashed crimson line signifies the scheme of routes influencing the burden updates belonging to the primary layer on panel (a) in the course of the error backpropagation method. A weight is linked to one of many output items by a number of routes (dashed crimson strains) and may exceed a million. You will need to observe that each one weights on the first layer are equated to the weights of 6 × (5 × 5), belonging to the six convolutional filters, as proven in Determine 1 (c).
The Tree-3 structure consists of M = 16 branches. The primary layer of every department consists of Okay (6 or 15) (5 × 5) filters for every of the three RGB channels. Every channel is convolved with its personal set of Okay filters, leading to 3 × Okay totally different filters. The convolutional layer filters are the identical for all M branches. The primary layer concludes with max-pooling consisting of non-overlapping (2 × 2) squares. Because of this, there are (14 × 14) output items for every filter. The second layer consists of a tree-like (non-overlapping) sampling (2 × 2 × 7 items) of Okay-filters for every RGB coloration in every department, leading to 21 output indicators (7 × 3) for every department. The third layer absolutely connects the outputs of 21 × M branches of layer 2 to 10 output modules. ReLU activation perform is used for on-line studying, whereas Sigmoid is used for offline studying.
In Determine 1 (d), the dashed black line marks the scheme of 1 route connecting the up to date weight on the first layer, as depicted in Determine 1 (c), in the course of the error backpropagation method to the output system.
To resolve the classification activity, researchers utilized the cross-entropy price perform and utilized the stochastic gradient descent algorithm to attenuate it. To fine-tune the mannequin, optimum hyperparameters corresponding to studying charge, momentum fixed, and weight decay coefficient had been discovered. To judge the mannequin, a number of validation datasets consisting of 10 000 random examples, just like the check dataset, had been used. The common outcomes had been calculated, contemplating the usual deviation from the acknowledged common success metrics. Nesterov’s technique and L2 regularization had been utilized within the examine.
Hyperparameters for offline studying, together with η (studying charge), μ (momentum fixed), and α (L2 regularization), had been optimized throughout offline studying, which concerned 200 epochs. Hyperparameters for on-line studying had been optimized utilizing three totally different dataset instance sizes.
Because of the experiment, an efficient method to coaching a tree-like structure, the place every weight is linked to the output unit by just one route, was demonstrated. This approximation to organic studying and the flexibility to make use of deep studying with drastically simplified dendritic timber of 1 or a number of neurons. You will need to observe that including a convolutional layer to the enter helps protect the tree-like construction and enhance success in comparison with architectures with out convolution.
Whereas the computational complexity of LeNet-5 was notably larger than that of the Tree-3 structure with comparable success charges, its environment friendly implementation necessitates new {hardware}. Additionally it is anticipated that coaching the tree-like structure will reduce the chance of gradient explosions, which is among the major challenges for deep studying. Introducing parallel branches as an alternative of the second convolutional layer in LeNet-5 improved success metrics whereas sustaining the tree-like construction. Additional investigation is warranted to discover the potential of large-scale and deeper tree-like architectures, that includes an elevated variety of branches and filters, to compete with modern CIFAR-10 success charges. This experiment, utilizing LeNet-5 as a place to begin, underscores the potential advantages of dendritic studying and its computational capabilities.