

Algunos tipos de aprendizaje automatico…
I. Aprendizaje supervisado
El objetivo principal del aprendizaje supervizado es aprender un modelo de datos de entrenamiento etiquetados, que nos permite hacer predicciones futuras o no vistas.
Conjunto de muestras donde las señales de salida deseadas (etiqueta) ya se conocen.
Caracteristicas:
- Datos etiquetados
- Suggestions directo
- Predicción de resultados futuros
Clasificacioón para predecir etiquetas de clase
Subcategoria del aprendizaje supervisado cuyo objetivo es predecir las etiquetas de clase categorica de nuevas instancias, basadas en observaciones pasadas.
Regresión para predecir resultados continuos
Subcategoria del aprendizaje supervisado cuyo objetivo es la predicción de datos continuos; tenemos un número de variables predictorias (explicativas) y una variable de respuesta continua … y tenemos que encontrar una relación entre estas variables que nos permitan predecir un resultado.
Resolver problemas interactivos con aprendizaje reforzado
Subcategoria del aprendizaje supervisado cuyo objetivo es desarrollar un sistema (agente) que mejore su rendimiento basado en interacciones con el entorno.Como la información sobre el estado precise del entorno normalmente tambien incluye una señal de recompensa, podemos pensar en el aprendizaje reforzado como un campo relacionado con el aprendizaje supervisado.
Un agente aprendera de su entorno mediante la observación de su estado y mediante su interacción atravez de una serie de acciones por las cuales va a recibir una recompensa.
El agente aprende todos los detalles mediante PRUEBA — ERROR porque realmente no conoce todos los detalles del entorno.
Ejemplo: Juego Pong
Agente: Programa que debe entender varias cosas.
Entorno: Debe entender los elementos del juego como que hay 2 jugadores, un tablero y una pelota.
Estado: el agente debe entender lo que esta sucediendo en el entorno, es decir, los movimientos de su oponente.
Acciones: Dependiendo el estado el agente debera aprender a moverse en el tablero para tratar de vencer a su oponente.
Recompensa: La manera de saber si lo hizo bien o no sera atravez del puntaje, si lo hace mal habran penalización en caso contrario una recompensa.
II. Aprendizaje sin supervición
El aprendizaje no supervisado es un tipo de aprendizaje automático en el que un modelo se entrena utilizando datos que no tienen etiquetas predefinidas. el aprendizaje no supervisado busca encontrar patrones ocultos o estructuras inherentes en los datos.
Es essential porque permite el análisis de grandes volúmenes de datos sin la necesidad de etiquetar manualmente cada dato. Esto es especialmente útil en situaciones donde el etiquetado es costoso o impráctico, y ayuda a descubrir información nueva y valiosa que puede no ser evidente a easy vista. Los modelos de aprendizaje no supervisados se utilizan para tres tareas principales: agrupamiento, asociación y reducción de dimensionalidad.
Técnicas de aprendizaje no supervizado
- Clustering (Agrupamiento):
Ok-means:
Descripción: Ok-means es un algoritmo que divide los datos en Ok grupos (clusters) según su similitud.
Funcionamiento: Inicialmente selecciona Ok centroides aleatorios, asigna cada punto de datos al centroide más cercano, y ajusta los centroides iterativamente hasta que las asignaciones ya no cambian significativamente.
Aplicaciones: Segmentación de clientes, agrupamiento de documentos.
Jerárquico:
Descripción: Este algoritmo construye una jerarquía de clusters de manera aglomerativa (de abajo hacia arriba) o divisiva (de arriba hacia abajo).
Funcionamiento: Comienza con cada punto de datos como un cluster particular person y fusiona los clusters más cercanos iterativamente.
Aplicaciones: Análisis de taxonomías, agrupación de genes en bioinformática.
DBSCAN:

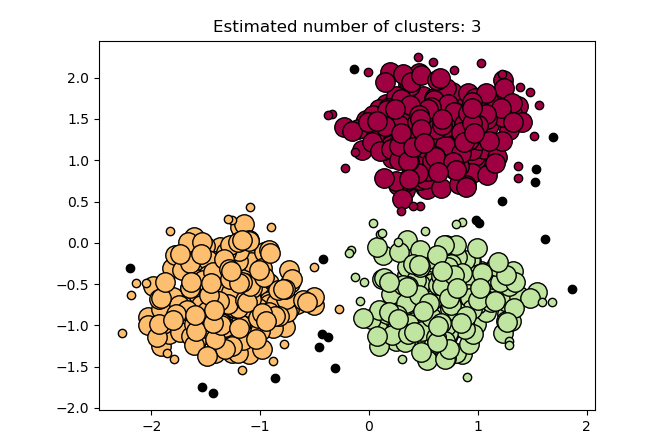{kind=link}
Funcionamiento: Agrupa puntos que están cerca unos de otros (según una distancia mínima) y marca puntos que no pertenecen a ningún cluster como ruido.
Aplicaciones: Detección de anomalías, análisis de imágenes.
- Reducción de Dimensionalidad:
PCA (Análisis de Componentes Principales):
Descripción: PCA scale back la dimensionalidad de los datos transformándolos a un nuevo conjunto de variables no correlacionadas (componentes principales).
Funcionamiento: Encuentra las direcciones de máxima variabilidad en los datos y proyecta los datos en estas direcciones.
Aplicaciones: Compresión de datos, visualización de datos de alta dimensión.
t-SNE (t-Distributed Stochastic Neighbor Embedding):
Descripción: Es una técnica para la reducción de dimensionalidad no lineal, adecuada para la visualización.
Funcionamiento: Modela cada punto de datos en un espacio de baja dimensión de manera que puntos similares en el espacio de alta dimensión se mantienen cercanos en el espacio de baja dimensión.
Aplicaciones: Visualización de datos de alta dimensión, exploración de datos.
Apriori:
Descripción: Algoritmo para encontrar reglas de asociación en bases de datos transaccionales.
Funcionamiento: Identifica conjuntos frecuentes de ítems y construye reglas de asociación a partir de estos conjuntos.
Aplicaciones: Análisis de mercado, recomendaciones de productos.
Algoritmo FP-Progress:
Descripción: Una alternativa al Apriori, más eficiente para encontrar conjuntos de ítems frecuentes.
Funcionamiento: Utiliza una estructura de datos llamada FP-tree para representar los datos de manera comprimida y generar conjuntos de ítems frecuentes sin realizar múltiples escaneos de la base de datos.
Aplicaciones: Reglas de asociación en grandes bases de datos.