
Let’s construct a customized mannequin from scratch for multiclass classification.

- Significance of constructing a customized mannequin
- Primary Constructing Blocks of a DL
- Practice and Take a look at Knowledge Prep
- Knowledge loader and Picture Augmentation
- Mannequin Structure and Coaching Config
- Placing every part collectively
- Coaching and Inference
- Conclusion
On the planet of deep studying, we frequently use pre-trained fashions which have been educated on large datasets. Nevertheless, there are occasions when constructing a customized mannequin from scratch is critical. Whether or not you’re new to ML or an skilled professional, you’ll possible must construct your individual fashions sooner or later.
Listed here are some key the explanation why constructing customized ML fashions is essential:
- Foundational Understanding: Be taught Mannequin Structure In the event you’re new to ML, constructing fashions from the bottom up helps you really perceive how neural community architectures work underneath the hood. This foundational information is invaluable.
- Tailor-made Options: Match for Your Use Case Pre-trained fashions might not all the time work nicely in your particular downside. Issues like mannequin dimension, inference pace, and required accuracy ranges could make off-the-shelf fashions unsuitable. Constructing a customized mannequin lets you tailor it precisely to your wants.
- Distinctive Knowledge Distributions: In case your information distribution could be very totally different from pre-trained mannequin coaching datasets, pre-trained fashions might not work nicely. Customized fashions educated in your particular information can carry out higher.
Learn this my different article to know the important ideas powering neural networks.
Whether or not you’re fine-tuning or making a customized mannequin, you’ll want these major parts:
i. Knowledge Loader & Augmenter
- Converts pictures into numerical information the mannequin can course of.
- Varied strategies accessible for outlining the information loader.
- Augmenter transforms pictures throughout coaching, serving to the mannequin deal with real-world information variations
ii. Mannequin Structure:
- Generally is a customized design (which we’ll cowl within the subsequent part) or a pre-trained mannequin.
iii. Mannequin Hyperparameters:
- Embrace Studying Fee, L1 & L2 Regularizers, Momentum, and so on.
- Information how mannequin weights replace
- Instance: A really small studying price prevents important weight updates after every batch, decreasing overfitting
iv. Loss Perform:
- Essential for mannequin efficiency
- Determines how a lot to penalize mannequin errors
- Selecting the best loss operate is as essential as choosing the mannequin itself
v. Optimizer:
- Considers loss operate output and hyperparameters to replace mannequin weights
- Varied varieties accessible; choosing the correct one is significant to keep away from studying stagnation
vi. Coaching Script (Coaching loop)
- Choose the batch of pattern and passes (ahead cross) by way of the mannequin
- Calculates the batch loss with the loss operate
- Optimizer backpropagates by way of the mannequin and updates the mannequin weights
For our customized picture classifier mannequin, we’ll be utilizing a satellite tv for pc picture classification dataset accessible on Kaggle (https://www.kaggle.com/datasets/mahmoudreda55/satellite-image-classification).

This dataset includes 5,631 samples throughout 4 classes: cloudy, desert, green_area, and water.
After downloading the information, we’ll create a CSV file containing the picture paths and their corresponding labels. Then, we’ll cut up this information into coaching and take a look at units. Right here’s the code snippet to perform this:
# create a csv file with image_path and respective label
image_path_list = []
label_list = []for class_cat in os.listdir("information"):
for image_object in os.listdir(f"information/{class_cat}"):
image_path_list.append(f"information/{class_cat}/{image_object}")
label_list.append(f"{class_cat}")
df = pd.DataFrame()
df["image_path"] = image_path_list
df["label"] = label_list
# now cut up this major information to coach and take a look at
# Outline the cut up ratio
test_ratio = 0.20 # 20% of knowledge will go to check
# cut up the information
train_df, test_df = train_test_split(df, test_size=test_ratio,
stratify=df['label'],
random_state=42)
print(f"Authentic dataset form: {df.form}")
print(f"Practice dataset form: {train_df.form}")
print(f"Take a look at dataset form: {test_df.form}")
Above code performs the next steps:
- Iterates by way of the information listing to gather picture paths and labels.
- Creates a pandas DataFrame with the collected info.
- Splits the information into coaching and take a look at units utilizing
train_test_splitfrom scikit-learn. - Makes use of stratified sampling to make sure balanced illustration of every class in each units.
Right here’s the information distribution after splitting :

Now that we have now our prepare and take a look at information ready, we are able to proceed to outline the information loader, which will likely be essential for effectively feeding the information into our PyTorch mannequin throughout coaching and analysis.

After making ready our prepare and take a look at picture information in CSV recordsdata, we have to arrange the next parts:
- PyTorch picture transforms: These apply a set of transformations to the enter pictures, together with augmentations for coaching.
- A customized PyTorch Dataset class: This hundreds pictures from native paths and applies the outlined transformations.
- Practice and take a look at DataLoaders: These are liable for loading batches of pictures throughout coaching and inference.
Let’s have a look at every of those parts intimately.
PyTorch Picture Transforms for Practice and Take a look at
We are able to outline a bunch of picture transformations utilizing transforms.Compose([]), which accepts an inventory of augmentation choices.
Right here’s the code :
IMAGE_SIZE = 124# this will likely be used throughout coaching, this may maintain all of the augmentation/transformation configs
training_transform = transforms.Compose([transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
# this will likely be used throughout testing / infernece, wo don't need any form of further transformation utilized on the time of operating mannequin prediction in take a look at / manufacturing inviroment
test_transform = transforms.Compose([transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
Observe that we don’t apply any augmentations in
test_transform. This ensures that in testing or inference, the mannequin receives the photographs of their authentic kind.
Customized PyTorch Dataset Class
The PyTorch Dataset helps load pictures from native storage to reminiscence, applies the outlined transformations, and returns normalized torch tensors to the DataLoader.
We are able to use default PyTorch Dataset to load the photographs from disk throughout coaching, however that comes with limitation, you’ll be able to refer this text I’ve written for more information on it.
Let’s have a look at the code to outline a customized PyTorch Dataset :
# Outline customized Dataset -> this may assist you load pictures out of your csv file
class CustomTrainingData(Dataset):
def __init__(self, csv_df, class_list, remodel=None):
self.df = csv_df
self.remodel = remodel
self.class_list = class_listdef __len__(self):
return self.df.form[0]
def __getitem__(self, index):
picture = Picture.open(self.df.iloc[index].image_path).convert('RGB')
label = self.class_list.index(self.df.iloc[index].label)
if self.remodel:
picture = self.remodel(picture)
return picture, label
Initialize the customized PyTorch dataset for prepare and take a look at:
train_data_object = CustomTrainingData(train_df, CLASS_LIST, training_transform)
test_data_object = CustomTrainingData(test_df, CLASS_LIST, test_transform)
PyTorch DataLoader
The DataLoader is liable for loading pictures in batches throughout coaching or testing. Right here’s the way it works:
- It selects a batch of indices, every pointing to an (image_path, label) pair.
- For every index, it calls
__getitem__(index)from our customized Dataset class. - The
__getitem__(index)methodology hundreds the picture, applies transformations, and returns the tensor.
Right here’s the code to create DataLoaders for our prepare and take a look at datasets:
BATCH_SIZE = 32# now outline dataloader, this may load the photographs batches from CustomTrainingData object
train_loader = DataLoader(train_data_object, batch_size=BATCH_SIZE, shuffle=True, num_workers=4)
test_loader = DataLoader(test_data_object, batch_size=BATCH_SIZE, shuffle=False, num_workers=4)
Observe: We’ve added
num_workers=4to probably pace up information loading through the use of a number of processes.
With the information preparation full, we are able to now transfer on to creating our customized mannequin.
Excessive Degree Structure of our mannequin

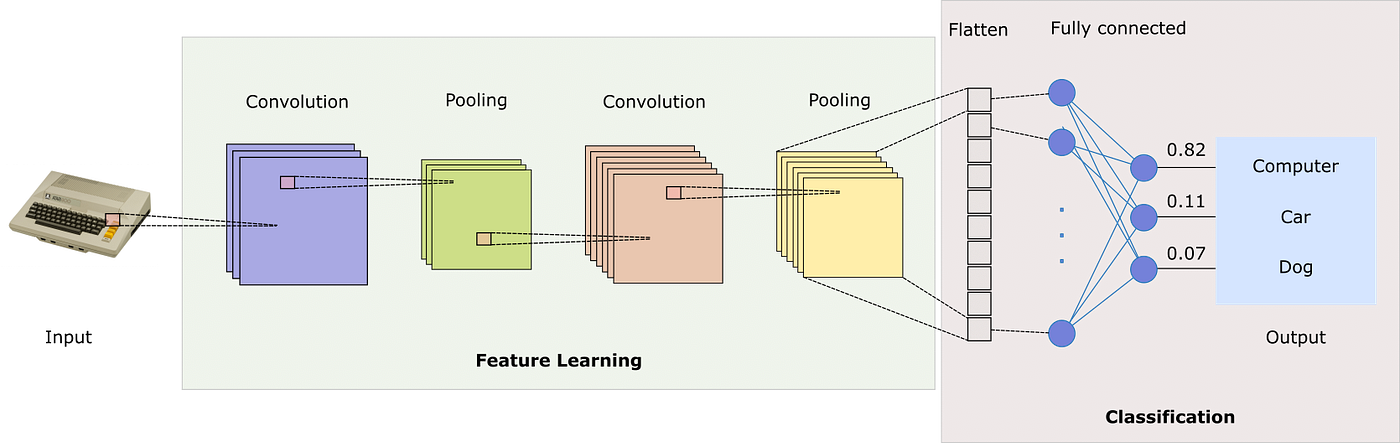{kind=link}
Our picture classification mannequin consists of two major elements:
- Characteristic studying and extraction: Convolutional and Pooling layers that be taught and extract options from the enter pictures.
- Classification: Totally linked (dense) layers that use the extracted options to categorise the picture.
A flatten layer connects these two elements, changing the 3D output of the convolutional layers right into a 1D vector for the dense layers.
Inheriting from nn.Module for customized mannequin
We create our customized mannequin by inheriting from nn.Module
class SatelliteImageClassifier(nn.Module)
Inheriting nn.Module gives a regular interface for all neural community modules in PyTorch. It ensures our customized mannequin integrates seamlessly with PyTorch ecosystem.
There are numerous the explanation why inheriting nn.Module to customized mannequin is essential :
i. Automated Parameter Administration
- Whenever you outline layers as attributes of your class,
nn.Modulemechanically registers them as parameters of your mannequin. - This permits PyTorch to mechanically observe all learnable parameters for operations like optimization and serialization.
ii. GPU/CPU Compatibility
nn.Modulegives strategies like.to(system)that transfer all parameters to the required system (CPU or GPU) effectively.
iii. State Administration
- It gives strategies to handle the mannequin’s state, like
.prepare()and.eval(), that are essential for processes like batch normalization and dropout.
iv. Serialization
nn.Moduleimplements strategies for saving and loading mannequin states, making it simple to avoid wasting and cargo your educated fashions.
v. Ahead Technique
- By inheriting from
nn.Module, you are required to implement aaheadmethodology, which defines the computation carried out at each name.
Outline Initializer methodology (init)
Within the class initializer methodology, we outline all the category variables and mannequin layers. That is the place you arrange the construction of your neural community.
We’ll outline the convolution layers, dropout, batch normalization, max/min/avg pooling, dense layers — principally what it’s worthwhile to construct the mannequin structure. These layers mechanically get registered as a part of the mannequin’s parameters.
Let’s have a look at code :
class SatelliteImageClassifier(nn.Module):
def __init__(self, num_classes, input_size=(128, 128), channels=3):
tremendous(SatelliteImageClassifier, self).__init__()self.input_size = input_size
self.channels = channels
# Convolutional layers
self.conv1 = nn.Conv2d(channels, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.conv4 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
# Batch normalization layers
self.bn1 = nn.BatchNorm2d(32)
self.bn2 = nn.BatchNorm2d(64)
self.bn3 = nn.BatchNorm2d(128)
self.bn4 = nn.BatchNorm2d(256)
# Max pooling layer
self.pool = nn.MaxPool2d(2, 2)
# Dropout layer
self.dropout = nn.Dropout(0.5)
# Calculate the dimensions of the flattened options
self._to_linear = None
self._calculate_to_linear(input_size)
# Totally linked layers
self.fc1 = nn.Linear(self._to_linear, 512)
self.fc2 = nn.Linear(512, num_classes)
Within the above code:
- Convolution and MaxPool Layers are for function extraction, serving to to extract essential options like form, texture, coloration, and so on., from the picture.
- Batch Normalization (bn) and Dropout layers are there for regularizing the mannequin throughout coaching in order that the mannequin doesn’t overfit.
- Totally linked (FC) layers are dense layers which take the flattened output of extracted options and assist in classifying the picture to the correct class.
We’ll see all of the layers in motion within the Ahead() methodology, simply bear with me 🙂
_calculate_to_linear() methodology
- This operate calculates the dimensions of the flattened options given the enter picture dimension.
_to_linearoutlined within the init class maintains the dimensions of the flattened layer output.
Right here’s code:
def _calculate_to_linear(self, input_size):
# This operate calculates the dimensions of the flattened options
x = torch.randn(1, self.channels, *input_size)
self.conv_forward(x)
The ahead methodology (the actual deal)
The ahead() methodology is core to constructing PyTorch fashions and it does lots of work underneath the hood.
The core performance of
ahead()methodology is to defines the computation carried out on the enter information like how how information flows by way of the layers of your neural community.
Once we name the mannequin on an enter (e.g., output = mannequin(enter)), PyTorch mechanically invokes the ahead() methodology.
ahead() methodology helps outline the community structure:
- It’s the place we implement the precise sequence of operations that remodel the enter to the output.
- We outline how the layers work together and in what order they’re utilized.
- We are able to name different modules or strategies inside
ahead(), permitting for modular design of advanced networks.
Let’s have a look at the code :
def conv_forward(self, x):
x = self.pool(F.relu(self.bn1(self.conv1(x))))
x = self.pool(F.relu(self.bn2(self.conv2(x))))
x = self.pool(F.relu(self.bn3(self.conv3(x))))
x = self.pool(F.relu(self.bn4(self.conv4(x))))if self._to_linear is None:
self._to_linear = x[0].form[0] * x[0].form[1] * x[0].form[2]
return x
def ahead(self, x):
x = self.conv_forward(x)
# Flatten the output for the totally linked layer
x = x.view(-1, self._to_linear)
# Totally linked layers with ReLU and dropout
x = self.dropout(F.relu(self.fc1(x)))
x = self.fc2(x)
return x
In above code `conv_forward` :
In every line, we have now outlined the identical computation, simply that the conv or bn layers change. Let’s take one conv + pooling layer for instance:
x = self.pool(F.relu(self.bn1(self.conv1(x))))
- First, we cross the enter by way of
self.conv1()convolution layer - Then the output is handed on to
self.bn1()batch normalization - The ReLU activation operate is utilized to the bn1 output
- Output from ReLU is handed on to
self.pool()pooling layer.
The simplified type of this one-liner could be written as:
# Apply convolution
x = self.conv1(x)
# Apply batch normalization
x = self.bn1(x)
# Apply ReLU activation operate
x = F.relu(x)
# Apply max pooling
x = self.pool(x)
Within the above code, ahead:
conv_forward(self, x)known as inside ahead, exhibiting how we are able to have modular design of neural networks.- First, the enter is handed by way of
conv_forwardwhich applies convolution and pooling on the enter. - Then
x.view(-1, self._to_linear)flattens the output from convolution/function extraction - After which the flattened output is handed on to the totally linked layers.
We are able to use Python management movement (if statements, loops) inside
ahead(), permitting for extra advanced and versatile architectures. We are able to additionally implement customized operations or logic that are not pre-defined PyTorch layers.
Full mannequin structure code :
class SatelliteImageClassifier(nn.Module):
def __init__(self, num_classes, input_size=(128, 128), channels=3):
tremendous(SatelliteImageClassifier, self).__init__()self.input_size = input_size
self.channels = channels
# Convolutional layers
self.conv1 = nn.Conv2d(channels, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.conv4 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
# Batch normalization layers
self.bn1 = nn.BatchNorm2d(32)
self.bn2 = nn.BatchNorm2d(64)
self.bn3 = nn.BatchNorm2d(128)
self.bn4 = nn.BatchNorm2d(256)
# Max pooling layer
self.pool = nn.MaxPool2d(2, 2)
# Dropout layer
self.dropout = nn.Dropout(0.5)
# Calculate the dimensions of the flattened options
self._to_linear = None
self._calculate_to_linear(input_size)
# Totally linked layers
self.fc1 = nn.Linear(self._to_linear, 512)
self.fc2 = nn.Linear(512, num_classes)
def _calculate_to_linear(self, input_size):
# This operate calculates the dimensions of the flattened options
x = torch.randn(1, self.channels, *input_size)
self.conv_forward(x)
def conv_forward(self, x):
x = self.pool(F.relu(self.bn1(self.conv1(x))))
x = self.pool(F.relu(self.bn2(self.conv2(x))))
x = self.pool(F.relu(self.bn3(self.conv3(x))))
x = self.pool(F.relu(self.bn4(self.conv4(x))))
if self._to_linear is None:
self._to_linear = x[0].form[0] * x[0].form[1] * x[0].form[2]
return x
def ahead(self, x):
x = self.conv_forward(x)
# Flatten the output for the totally linked layer
x = x.view(-1, self._to_linear)
# Totally linked layers with ReLU and dropout
x = self.dropout(F.relu(self.fc1(x)))
x = self.fc2(x)
return x
Mannequin Hyperparameters and Config
Let’s outline some mannequin hyperparameters and config. We’ll use these within the coaching script and a few whereas initializing the mannequin.
# record of courses in your dataset
CLASS_LIST = ['water', 'cloudy', 'desert', 'green_area']# Hyperparameters
BATCH_SIZE = 124
BATCH_SIZE = 32
EPOCHS = 25
LEARNING_RATE = 0.001
NUM_CLASSES = len(CLASS_LIST)
INPUT_SIZE = (IMAGE_SIZE, IMAGE_SIZE)
CHANNELS = 3
# Gadget configuration
system = torch.system('cuda' if torch.cuda.is_available() else 'cpu')
Initialize our Customized Mannequin
We are able to create the mannequin by initializing the SatelliteImageClassifier with NUM_CLASSES, INPUT_SIZE, and CHANNELS.
We’ll assign the mannequin to GPU with .to(system). This may choose the accessible GPU; in any other case, it should load the mannequin on CPU.
# Initialize the mannequin
mannequin = SatelliteImageClassifier(NUM_CLASSES, INPUT_SIZE, CHANNELS).to(system)
Let’s set the optimizer with the training price. We’re utilizing Adam on this occasion, and CrossEntropyLoss as our loss operate.
# Loss operate and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(mannequin.parameters(), lr=LEARNING_RATE)
To see the overall variety of parameters:
# If you wish to see the variety of parameters
total_params = sum(p.numel() for p in mannequin.parameters())
print(f"Complete variety of parameters: {total_params}")

Let’s print the mannequin :


To date, we’ve coated the next key steps in constructing our customized PyTorch picture classifier:
i. Knowledge Preparation:
- We outlined picture transformations:
training_transformandtest_transform - We created a Customized Dataset class for each coaching and testing information
- We initialized
train_data_objectandtest_data_objectutilizing our customized dataset class
ii. Knowledge Loading:
- We created PyTorch DataLoaders (
train_loaderandtest_loader) to effectively load batches of pictures throughout coaching and testing
iii. Mannequin Structure:
- We outlined a customized class
SatelliteImageClassifierthat inherits fromnn.Module - We applied the
__init__methodology to arrange our mannequin’s layers - We created the
aheadmethodology to outline how information flows by way of our community
iv. Mannequin Initialization:
- We initialized our customized mannequin with the suitable parameters
v. Coaching Setup:
- We outlined the optimizer (Adam) to replace our mannequin’s parameters
- We selected an applicable loss operate (CrossEntropyLoss) for our multi-class classification process
Now that we have now all these parts in place, we’re able to carry them collectively in a coaching loop and begin coaching our mannequin.
The coaching loop is the guts of the mannequin coaching course of. It includes operating the identical sequence of steps for a sure variety of epochs (iterations). Throughout every epoch:
- We choose batches of pictures and cross them by way of the mannequin
- We calculate the loss for every batch utilizing our outlined loss operate
- We use the optimizer to replace the mannequin weights based mostly on the calculated loss.
Right here’s code for the coaching loop :
Please notice, this coaching script is extremely simplified. Many essential components similar to logging, plotting, saving finest and final weights, utilizing callbacks, and integrating TensorBoard have been omitted to keep up simplicity..
# Coaching loop
for epoch in vary(EPOCHS):
mannequin.prepare()
running_loss = 0.0
for pictures, labels in train_loader:
pictures = pictures.to(system)
labels = labels.to(system)optimizer.zero_grad()
outputs = mannequin(pictures)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.merchandise()
print(f'Epoch [{epoch+1}/{EPOCHS}], Loss: {running_loss/len(train_loader):.4f}')
# Validation
mannequin.eval()
all_predictions = []
all_labels = []
with torch.no_grad():
for pictures, labels in test_loader:
pictures = pictures.to(system)
labels = labels.to(system)
outputs = mannequin(pictures)
_, predicted = torch.max(outputs.information, 1)
all_predictions.prolong(predicted.cpu().numpy())
all_labels.prolong(labels.cpu().numpy())
# Calculate metrics
accuracy = 100 * sum(np.array(all_predictions) == np.array(all_labels)) / len(all_labels)
precision = precision_score(all_labels, all_predictions, common='weighted')
recall = recall_score(all_labels, all_predictions, common='weighted')
f1 = f1_score(all_labels, all_predictions, common='weighted')
print(f'Epoch [{epoch+1}/{EPOCHS}]')
print(f'Accuracy on take a look at set: {accuracy:.2f}%')
print(f'Precision: {precision:.4f}')
print(f'Recall: {recall:.4f}')
print(f'F1 Rating: {f1:.4f}')
print('-----------------------------')
print('Coaching completed!')
# Save the mannequin
torch.save(mannequin.state_dict(), 'satellite_classifier.pth')

Let’s break down some key parts of this coaching loop:
mannequin.prepare()andmannequin.eval(): These set the mannequin for coaching and analysis modes respectively. In eval mode,mannequin.eval()disables regularization methods like dropout and batch normalization, that are solely used throughout coaching.optimizer.zero_grad(): This resets the gradients of all parameters to zero earlier than the backward cross. It’s a necessity as a result of PyTorch accumulates gradients by default.loss = criterion(outputs, labels): This calculates the loss for the given batch utilizing our outlined loss operate.loss.backward(): This computes the gradient of the loss with respect to the mannequin parameters.optimizer.step(): This updates the mannequin parameters based mostly on the computed gradients.with torch.no_grad():: This context supervisor is used throughout validation to disable gradient calculation, which hastens computation and reduces reminiscence utilization.torch.save(mannequin.state_dict(), 'satellite_classifier.pth'): This protects the mannequin weights on the finish of coaching.
I might extremely extremely suggest studying this text, on this article i’ve coated a number of side of effective tuning mannequin in PyTorch, give it a learn :
Now that we’ve educated our mannequin and saved it to disk, let’s transfer on to loading the mannequin and operating inference on new information.
After coaching our mannequin and saving it to disk, we are able to load it for inference on new pictures. Let’s undergo the method step-by-step.
Loading the Saved Mannequin
We are able to load the mannequin that we saved earlier utilizing torch.load(). This is the script to take action:
# Gadget configuration
system = torch.system('cuda' if torch.cuda.is_available() else 'cpu')# load mannequin weight
mannequin = torch.load('satellite_classifier.pth')
mannequin.load_state_dict(mannequin)
mannequin.to(system).eval()
Outline Picture Transforms and Class Checklist
We have to be certain that we course of new pictures in the identical means as our coaching information:
# this will likely be used throughout testing / infernece, wo don't need any form of further transformation utilized on the time of operating mannequin prediction in take a look at / manufacturing inviroment
test_transform = transforms.Compose([transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])CLASS_LIST = ['water', 'cloudy', 'desert', 'green_area'] # record of courses in your dataset
Helper Perform to Plot Pictures
Let’s create a operate to show the photographs we’re classifying:
def plot_image(picture):
"""
Plot a picture utilizing matplotlib.Parameters:
picture : PIL.Picture or numpy.ndarray
The picture to be plotted. Generally is a PIL Picture object or a numpy array.
"""
# Convert PIL Picture to numpy array if crucial
if isinstance(picture, Picture.Picture):
picture = np.array(picture)
plt.imshow(picture)
plt.axis('off') # Disguise axes
plt.present()
Inference Perform
Now, let’s write a operate that takes a picture path as an argument, plots the picture, and prints the mannequin’s prediction:
# Inference script
def predict(image_path):
image_pil = Picture.open(image_path).convert('RGB')
picture = test_transform(image_pil).unsqueeze(0).to(system)with torch.no_grad():
output = mannequin(picture)
# Apply softmax to the output
softmax_output = F.softmax(output, dim=1)
print(f'Mannequin uncooked output: {output}')
print(f'Softmax output: {softmax_output}')
# Get the anticipated class and its confidence
confidence, predicted = torch.max(softmax_output, 1)
predicted_class = CLASS_LIST[predicted.item()]
confidence = confidence.merchandise()
print(f'Predicted class: {predicted_class}')
print(f'Confidence: {confidence:.4f}')
plot_image(image_pil)
Working Inference
Now we are able to use our predict_image operate to categorise new pictures:
Instance 1:

Mannequin uncooked output: tensor([[ -1.5463, -5.0433, -20.4949, 23.9693]], system='cuda:0')
Softmax output: tensor([[8.2927e-12, 2.5117e-13, 4.8916e-20, 1.0000e+00]], system='cuda:0')
Predicted class: green_area
Confidence: 1.0000
Instance 2:

Mannequin uncooked output: tensor([[ 4.0157, -7.6036, -12.5321, 3.6128]], system='cuda:0')
Softmax output: tensor([[5.9936e-01, 5.3889e-06, 3.9004e-08, 4.0063e-01]], system='cuda:0')
Predicted class: water
Confidence: 0.5994
On this article, we’ve explored the assorted facets of making a customized picture classification mannequin in PyTorch. We’ve coated a complete journey from information preparation to mannequin inference, referring to a number of essential parts:
- Knowledge Preparation: We discovered create customized datasets and use PyTorch’s DataLoader for environment friendly batch processing.
- Mannequin Structure: We delved into the construction of a PyTorch mannequin by subclassing
nn.Module. We explored essential strategies like__init__()andahead(), and understood how they contribute to defining our mannequin’s structure. - Coaching Course of: We applied a coaching loop, incorporating ideas like loss calculation, backpropagation, and optimization.
- Mannequin Analysis: We included validation steps in our coaching course of to observe our mannequin’s efficiency on unseen information.
- Inference: Lastly, we discovered save our educated mannequin, load it, and use it for making predictions on new pictures.
All through this course of, we’ve gained hands-on expertise with key PyTorch ideas and finest practices for constructing customized neural networks. This basis could be prolonged to extra advanced architectures and utilized to a variety of pc imaginative and prescient duties past satellite tv for pc picture classification.