
Introduction
Within the area of machine studying, creating strong and correct predictive fashions is a main goal. Ensemble studying strategies excel at enhancing mannequin efficiency, with bagging, quick for bootstrap aggregating, enjoying an important function in lowering variance and bettering mannequin stability. This text explores bagging, explaining its ideas, purposes, and nuances, and demonstrates the way it makes use of a number of fashions to enhance prediction accuracy and reliability.
Overview
- Perceive the basic idea of Bagging and its objective in lowering variance and enhancing mannequin stability.
- Describe the steps concerned in placing Bagging into observe, akin to making ready the dataset, bootstrapping, coaching the mannequin, producing predictions, and merging predictions.
- Acknowledge the numerous advantages of bagging, together with its capability to scale back variation, mitigate overfitting, stay resilient within the face of outliers, and be utilized to a wide range of machine studying issues.
- Achieve sensible expertise by implementing Bagging for a classification activity utilizing the Wine dataset in Python, using the scikit-learn library to create and consider a BaggingClassifier.
What’s Bagging?
Bagging is a machine studying ensemble methodology geared toward bettering the reliability and accuracy of predictive models. It entails producing a number of subsets of the coaching information utilizing random sampling with substitute. These subsets are then used to coach a number of base fashions, akin to determination timber or neural networks.
When making predictions, the outputs from these base fashions are mixed, typically by averaging (for regression) or voting (for classification), to provide the ultimate prediction. Bagging reduces overfitting by creating variety among the many fashions and enhances general efficiency by decreasing variance and rising robustness.
Implementation Steps of Bagging
Right here’s a common define of implementing Bagging:
- Dataset Preparation: Clear and preprocess your dataset. Cut up it into coaching and take a look at units.
- Bootstrap Sampling: Randomly pattern from the coaching information with substitute to create a number of bootstrap samples. Every pattern usually has the identical dimension as the unique dataset.
- Mannequin Coaching: Prepare a base mannequin (e.g., determination tree, neural community) on every bootstrap pattern. Every mannequin is educated independently.
- Prediction Technology: Use every educated mannequin to foretell the take a look at information.
- Combining Predictions: Mixture the predictions from all fashions utilizing strategies like majority voting for classification or averaging for regression.
- Analysis: Assess the ensemble’s efficiency on the take a look at information utilizing metrics like accuracy, F1 rating, or imply squared error.
- Hyperparameter Tuning: Alter the hyperparameters of the bottom fashions or the ensemble as wanted, utilizing strategies like cross-validation.
- Deployment: As soon as happy with the ensemble’s efficiency, deploy it to make predictions on new information.
Additionally Learn: Top 10 Machine Learning Algorithms to Use in 2024
Understanding Ensemble Studying
To extend efficiency general, ensemble studying integrates the predictions of a number of fashions. By combining the insights from a number of fashions, this methodology continuously produces forecasts which might be extra correct than these of anyone mannequin alone.
Common ensemble strategies embody:
- Bagging: Includes coaching a number of base fashions on totally different subsets of the coaching information created by random sampling with substitute.
- Boosting: A sequential methodology the place every mannequin focuses on correcting the errors of its predecessors, with in style algorithms like AdaBoost and XGBoost.
- Random Forest: An ensemble of determination timber, every educated on a random subset of options and information, with ultimate predictions made by aggregating particular person tree predictions.
- Stacking: Combines the predictions of a number of base fashions utilizing a meta-learner to provide the ultimate prediction.
Advantages of Bagging
- Variance Discount: By coaching a number of fashions on totally different information subsets, Bagging reduces variance, resulting in extra steady and dependable predictions.
- Overfitting Mitigation: The variety amongst base fashions helps the ensemble generalize higher to new information.
- Robustness to Outliers: Aggregating a number of fashions’ predictions reduces the impression of outliers and noisy information factors.
- Parallel Coaching: Coaching particular person fashions may be parallelized, dashing up the method, particularly with giant datasets or advanced fashions.
- Versatility: Bagging may be utilized to varied base learners, making it a versatile approach.
- Simplicity: The idea of random sampling with substitute and mixing predictions is simple to grasp and implement.
Functions of Bagging
Bagging, also called Bootstrap Aggregating, is a flexible approach used throughout many areas of machine studying. Right here’s a take a look at the way it helps in varied duties:
- Classification: Bagging combines predictions from a number of classifiers educated on totally different information splits, making the general outcomes extra correct and dependable.
- Regression: In regression issues, bagging helps by averaging the outputs of a number of regressors, resulting in smoother and extra correct predictions.
- Anomaly Detection: By coaching a number of fashions on totally different information subsets, bagging improves how effectively anomalies are noticed, making it extra immune to noise and outliers.
- Function Choice: Bagging might help establish crucial options by coaching fashions on totally different function subsets. This reduces overfitting and improves mannequin efficiency.
- Imbalanced Information: In classification issues with uneven class distributions, bagging helps steadiness the courses inside every information subset. This results in higher predictions for much less frequent courses.
- Constructing Highly effective Ensembles: Bagging is a core a part of advanced ensemble strategies like Random Forests and Stacking. It trains various fashions on totally different information subsets to attain higher general efficiency.
- Time-Sequence Forecasting: Bagging improves the accuracy and stability of time-series forecasts by coaching on varied historic information splits, capturing a wider vary of patterns and traits.
- Clustering: Bagging helps discover extra dependable clusters, particularly in noisy or high-dimensional information. That is achieved by coaching a number of fashions on totally different information subsets and figuring out constant clusters throughout them.
Bagging in Python: A Temporary Tutorial
Allow us to now discover tutorial on bagging in Python.
# Importing mandatory libraries
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load the Wine dataset
wine = load_wine()
X = wine.information
y = wine.goal
# Cut up the dataset into coaching and testing units
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,
random_state=42)
# Initialize the bottom classifier (on this case, a call tree)
base_classifier = DecisionTreeClassifier()
# Initialize the BaggingClassifier
bagging_classifier = BaggingClassifier(base_estimator=base_classifier,
n_estimators=10, random_state=42)
# Prepare the BaggingClassifier
bagging_classifier.match(X_train, y_train)
# Make predictions on the take a look at set
y_pred = bagging_classifier.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
This instance demonstrates the right way to use the BaggingClassifier from scikit-learn to carry out Bagging for classification duties utilizing the Wine dataset.
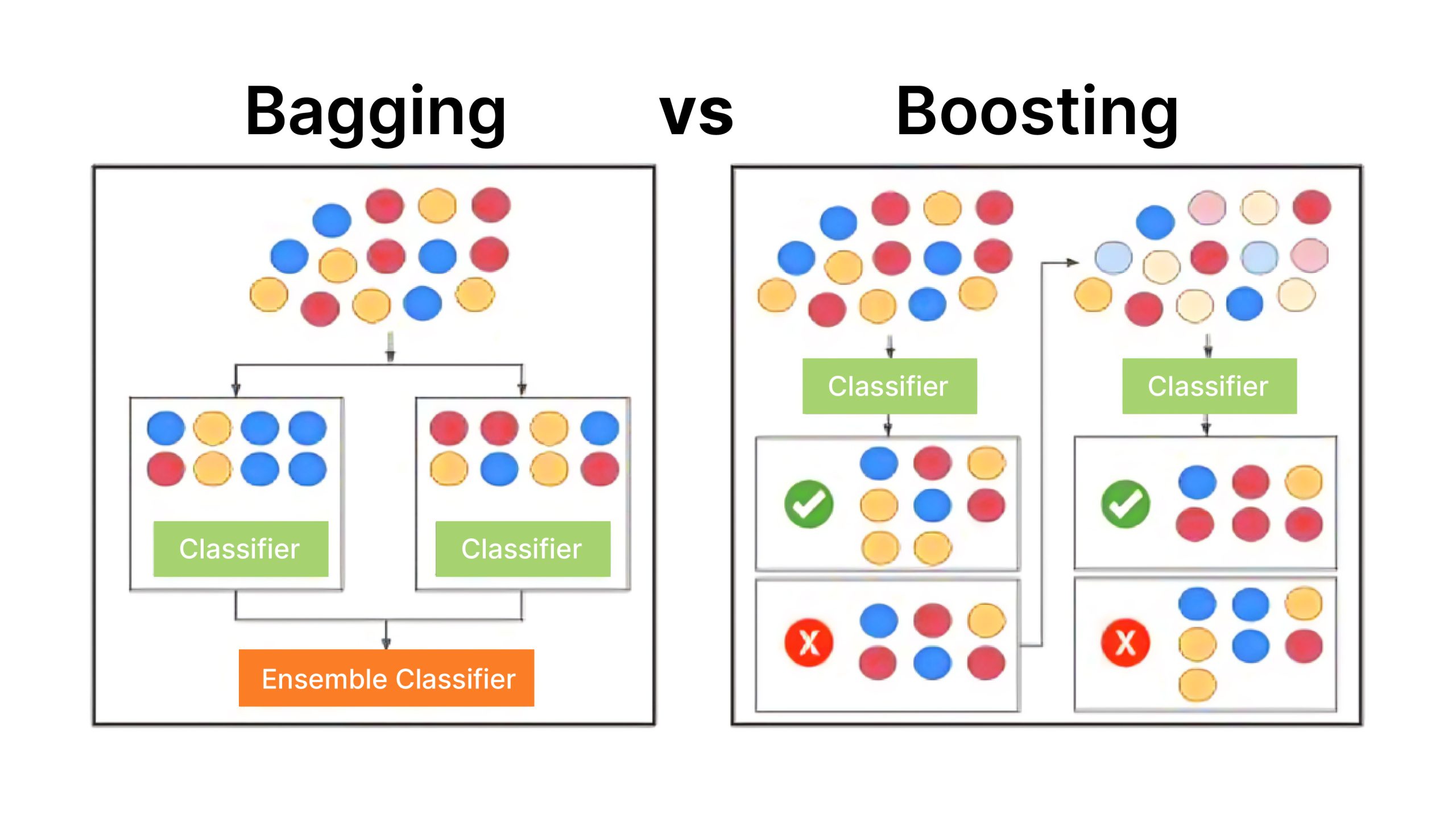
Variations Between Bagging and Boosting
Allow us to now discover distinction between bagging and boosting.
| Function | Bagging | Boosting |
| Kind of Ensemble | Parallel ensemble methodology | Sequential ensemble methodology |
| Base Learners | Skilled in parallel on totally different subsets of the info | Skilled sequentially, correcting earlier errors |
| Weighting of Information | All information factors equally weighted | Misclassified factors given extra weight |
| Discount of Bias/Variance | Primarily reduces variance | Primarily reduces bias |
| Dealing with of Outliers | Resilient to outliers | Extra delicate to outliers |
| Robustness | Usually strong | Much less strong to outliers |
| Mannequin Coaching Time | Could be parallelized | Usually slower attributable to sequential coaching |
| Examples | Random Forest | AdaBoost, Gradient Boosting, XGBoost |
Conclusion
Bagging is a strong but easy ensemble methodology that strengthens mannequin efficiency by decreasing variation, enhancing generalization, and rising resilience. Its ease of use and skill to coach fashions in parallel make it in style throughout varied purposes.
Regularly Requested Questions
A. Bagging in machine studying reduces variance by introducing variety among the many base fashions. Every mannequin is educated on a unique subset of the info, and when their predictions are mixed, errors are inclined to cancel out. This results in extra steady and dependable predictions.
A. Bagging may be computationally intensive as a result of it entails coaching a number of fashions. Nonetheless, the coaching of particular person fashions may be parallelized, which might mitigate among the computational prices.
A. Bagging and Boosting are each ensemble strategies however makes use of totally different method. Bagging trains base fashions in parallel on totally different information subsets and combines their predictions to scale back variance. Boosting trains base fashions sequentially, with every mannequin specializing in correcting the errors of its predecessors, aiming to scale back bias.