
Introduction
One of many hardest issues about making highly effective fashions in machine studying is twiddling with many ranges. Hyperparameter optimization—adjusting these settings to finish up with one thing that’s not horrible—could be a very powerful a part of all of it. On this weblog submit, full with code snippets, we’ll cowl what this implies and do it.
Overview
- Understand the importance of hyperparameters in machine studying fashions.
- Study numerous hyperparameter optimization strategies, corresponding to handbook tuning, grid search, random search, Bayesian optimization, and gradient-based optimization.
- Implementing hyperparameter optimization methods with well-liked libraries like scikit-learn and scikit-optimize
- Learn to select the fitting optimization technique relying on mannequin complexity, search area dimensionality, or out there computational assets
Getting Began With Optimization For Hyperparameters
To get began, we have to perceive hyperparameters. In a machine studying mannequin, we determine on these settings earlier than coaching begins. They management features just like the community structure and the variety of layers. Additionally they affect how the mannequin learns the information. For instance, when utilizing gradient descent, hyperparameters embody the educational charge. Regularization power may obtain comparable objectives however via solely completely different means.
Significance Of Hyperparameter Optimization
It ought to come as no shock then that the place these hyperparameters find yourself being set has large implications to your last outcome. You already know the take care of underfitting and overfitting, proper? Nicely, if not, simply assume again to when Winamp had skins; underfit fashions can not make the most of all out there info, while overfit ones don’t know what they have been skilled on. So we’re making an attempt to realize some Goldilocks scenario (i.e., excellent) the place our parameters generalize effectively throughout unseen examples with out sacrificing an excessive amount of efficiency on identified knowledge.
There are lots of methods to optimize hyperparameters, together with handbook tuning and automatic strategies. Beneath are some generally used methods:
- Guide Tuning: This methodology requires manually making an attempt completely different combos of hyperparameters and evaluating the mannequin’s efficiency. Though easy, it could take an excessive amount of time and show ineffective, significantly for fashions with quite a few hyperparameters.
- Grid Search: Grid search is an exhaustive analysis of all attainable combos of hyperparameters inside a specified vary. Though complete, it may be computationally costly, particularly for high-dimensional search areas.
- Random Search: Not like making an attempt out each mixture, random search selects hyperparameter values randomly from a specified distribution. It may be extra environment friendly than a grid search, particularly with giant areas.
- Bayesian Optimization: Bayesian optimization includes constructing a probabilistic mannequin that drives the search in the direction of optimum hyperparameters. It examines areas of curiosity whereas intelligently overlooking these that don’t present potential throughout the search area.
- Gradient-Primarily based Optimization: This treats hyperparameters as further parameters that may be improved utilizing strategies based mostly on gradients (e.g., stochastic gradient descent). Primarily, it’s efficient for differentiable hyperparameters corresponding to studying charges
Having lined the theoretical features, let’s have a look at some code examples to indicate how hyperparameter optimization will be applied virtually. This weblog submit will use Python with the scikit-learn library, which affords numerous instruments for tuning hyperparameters.
Instance 1: Grid Seek for Logistic Regression
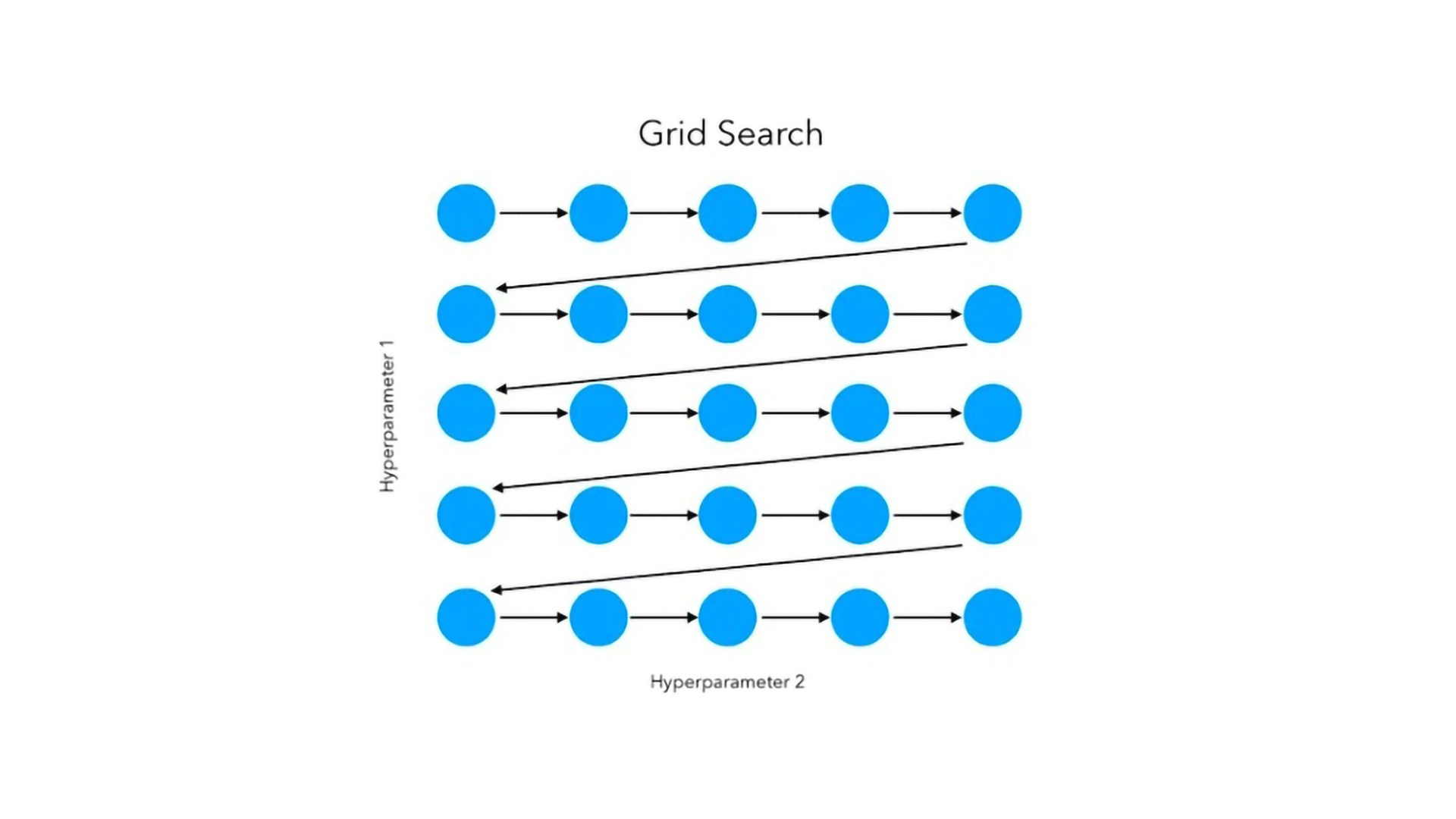
Suppose {that a} logistic regression mannequin wants regularisation power (C) optimization alongside penalty sort (penalty), then it may be completed by grid search, the place all attainable combos of those two hyper-parameters are tried till probably the most applicable one is discovered.
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
# Outline the hyperparameter grid
param_grid = {
'C': [0.001, 0.01, 0.1, 1, 10, 100],
'penalty': ['l1', 'l2']
}
# Create the logistic regression mannequin
mannequin = LogisticRegression()
# Carry out grid search
grid_search = GridSearchCV(mannequin, param_grid, cv=5, scoring='accuracy')
grid_search.match(X_train, y_train)
# Get the most effective hyperparameters and the corresponding rating
best_params = grid_search.best_params_
best_score = grid_search.best_score_
print(f"Finest hyperparameters: {best_params}")
print(f"Finest accuracy rating: {best_score}")On this instance, we outline a grid of hyperparameter values for the regularization power (C) and the penalty sort (penalty). We then use the `GridSearchCV` class from scikit-learn to carry out an exhaustive search over the desired grid, evaluating the mannequin’s efficiency utilizing 5-fold cross-validation and accuracy because the scoring metric. Lastly, we print the most effective hyperparameters and the corresponding accuracy rating.
Instance 2: Bayesian Optimization for a Random Forest Classifier
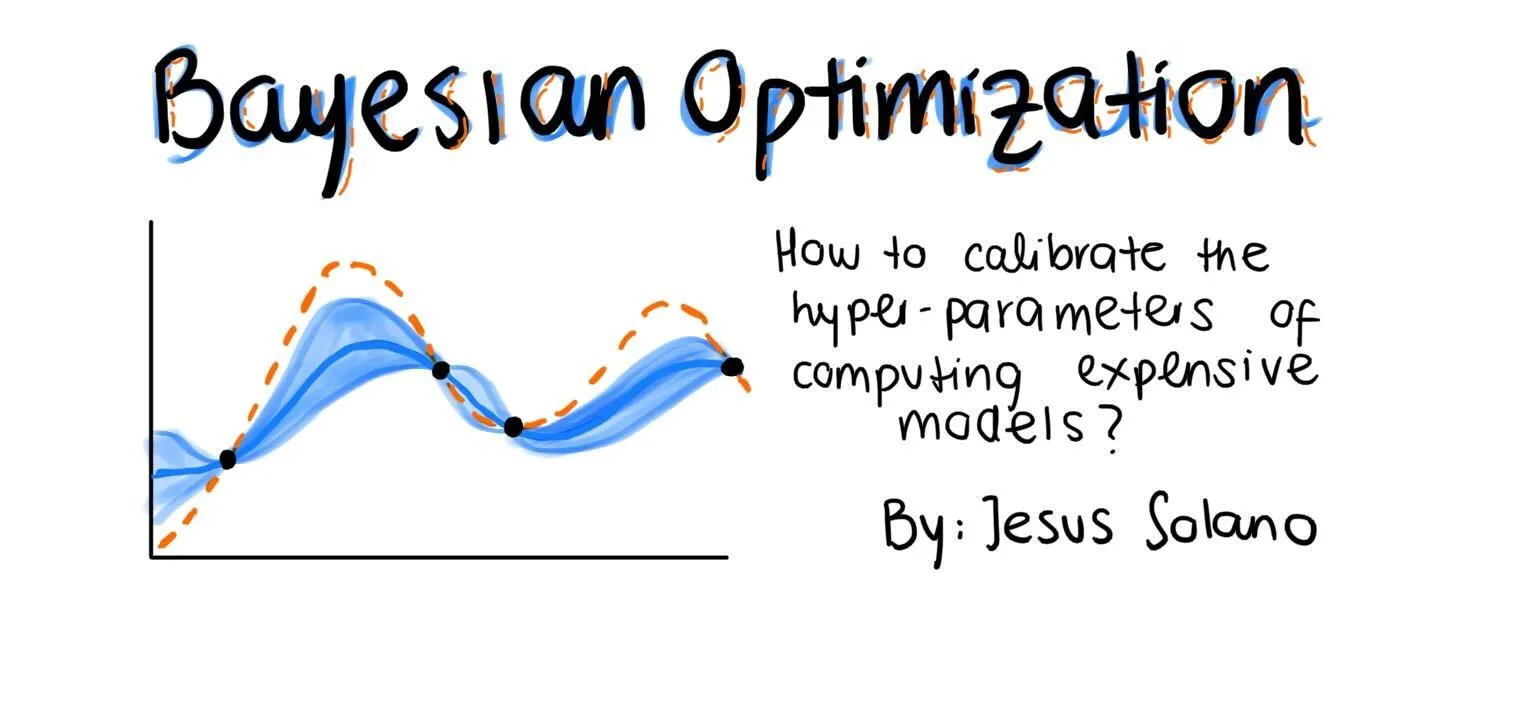
Bayesian optimization is a strong approach for hyperparameter tuning, particularly when coping with high-dimensional search areas or when the target perform is dear to judge. Let’s see how we are able to use it to optimize a random forest classifier:
from sklearn.ensemble import RandomForestClassifier
from skopt import BayesSearchCV
# Outline the search area
search_spaces = {
'max_depth': (2, 20),
'max_features': (1, 'log2'),
'n_estimators': (10, 500),
'min_samples_split': (2, 20),
'min_samples_leaf': (1, 10)
}
# Create the random forest mannequin
mannequin = RandomForestClassifier(random_state=42)
# Carry out Bayesian optimization
bayes_search = BayesSearchCV(
mannequin,
search_spaces,
n_iter=100,
cv=3,
scoring='accuracy',
random_state=42
)
bayes_search.match(X_train, y_train)
# Get the most effective hyperparameters and the corresponding rating
best_params = bayes_search.best_params_
best_score = bayes_search.best_score_
print(f"Finest hyperparameters: {best_params}")
print(f"Finest accuracy rating: {best_score}")
As an example, one could restrict the depth, the variety of options, and the variety of estimators and specify different hyperparameters like minimal samples required for splitting or leaf nodes in a random forest classifier. Right here, we make use of the “BayesSearchCV” class from the sci-kit-optimize library to conduct Bayesian optimization by performing 100 iterations with 3-fold cross-validation utilizing the accuracy rating metric, then displaying the most effective hyperparameters together with their corresponding accuracies.
Instance 3: Random Search with Optuna for a Random Forest Classifier
Let’s discover use Optuna to carry out a random seek for optimizing the hyperparameters of a random forest classifier:
import optuna
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import cross_val_score
# Load the breast most cancers dataset
knowledge = load_breast_cancer()
X, y = knowledge.knowledge, knowledge.goal
# Outline the target perform to optimize
def goal(trial):
max_depth = trial.suggest_int('max_depth', 2, 32)
n_estimators = trial.suggest_int('n_estimators', 100, 1000)
max_features = trial.suggest_categorical('max_features', ['auto', 'sqrt', 'log2'])
rf = RandomForestClassifier(max_depth=max_depth,
n_estimators=n_estimators,
max_features=max_features,
random_state=42)
rating = cross_val_score(rf, X, y, cv=5, scoring='accuracy').imply()
return rating
# Create an Optuna examine and optimize the target perform
examine = optuna.create_study(route='maximize')
examine.optimize(goal, n_trials=100)
# Print the most effective hyperparameters and the corresponding rating
print('Finest hyperparameters: ', examine.best_params)
print('Finest accuracy rating: ', examine.best_value)The examples above are only a few approaches and instruments that can be utilized whereas engaged on hyperparameter optimization duties. The choice course of ought to take into account components corresponding to mannequin complexity, search area dimensionality, or out there computational assets.
Key Takeaways
1. Hyperparameters drastically affect how effectively a machine studying mannequin performs; subsequently, choosing applicable values for them can result in greater accuracy and higher generalization.
2. There are alternative ways to go looking via hyperparameter areas, from manually to extra advanced methods corresponding to grid search, random search, bayesian optimization, or gradient descent should you’re feeling actually adventurous. However most individuals follow one thing easy like brute drive as a substitute.
One ought to recall that hyperparameter optimization is an iterative course of that may require fixed monitoring and adjustment of hyperparameters to realize the most effective efficiency.
Understanding and making use of methods for hyperparameter optimization can unlock the total potential of your machine studying fashions, which is able to lead to greater accuracy and generalization throughout numerous functions, amongst different issues.
Conclusion
Hyperparameter tuning is a crucial a part of creating profitable machine-learning fashions. If you discover this area systematically, discovering an optimum setup for them will assist unlock potentials hidden in your knowledge, main to higher accuracy generalization capabilities, amongst others.
Whether or not you select handbook tuning, grid search, random search, Bayesian optimization, or gradient-based strategies, understanding the ideas and methods of hyperparameter optimization will empower you to create strong and dependable machine-learning options.
Be a part of the Certified AI & ML BlackBelt Plus Program for customized studying tailor-made to your objectives, personalised 1:1 mentorship from business consultants, and devoted job placement help. Enroll now and remodel your future!
Steadily Requested Questions (FAQs)
A. Earlier than coaching begins, values for these settings are selected a model-wide foundation; they management its conduct, structure building, and studying course of execution, corresponding to however not restricted to studying charges, regularization strengths, numbers of hidden layers, and most depths for choice timber.
A. In any other case, poorly chosen hyperparameters may lead to underfitting (too easy fashions) or overfitting (memorizing coaching knowledge with out generalization). Subsequently, the principle concept behind this course of is discovering the most effective mixture that maximizes efficiency on a given job out of all attainable configurations.
A. Widespread methods contain handbook tuning, grid search, random search, Bayesian optimization, and gradient-based optimization. Every has strengths and weaknesses, and the selection depends upon components like mannequin complexity, search area dimensionality, and computational assets out there.
A. The reply depends upon numerous components corresponding to how easy or advanced your fashions are going to be; what’s the scale of the area via which we are able to discover these mannequin parameters (i.e., variety of dimensions); but additionally it closely depends upon how a lot CPU time/ GPU time however then they’re extra possible speaking about RAM reminiscence.