
There may be loads of supply to learn the way Gradient Descent works and the way you should utilize it. My function right here is to elucidate the idea in a quite simple method. Typically we attempt to decrease error therefore Gradient Descent is extra well-liked than Gradient Ascent within the Machine Studying world.
Let’s assume that you’ve got some enter values(information) and a few output values(labels). In fact you wish to discover the perform given an enter worth it outputs your anticipated output worth. It is a basic begin level of a ML drawback.
x = [-5, -4, -4, -4, -4, -4, -3, -2, -1, -1, -1, 0, 0, 0, 0, 1, 1, 1, 3, 3]
y = [-15, -13, -13, -13, -13, -13, -11, -9, -7, -7, -7, -5, -5, -5, -5, -3, -3, -3, 1, 1]
Simply wanting on the numbers it isn’t clear what it represents so let’s plot them to grasp the issue extra.

Wanting on the graph it’s clear that it’s a linear drawback. As a result of it’s a linear drawback we will assume that it has a components like y = Ax + B. (That is the half the place you determine which ML mannequin you’re going to use)
Now we’ve got x, y and a components/mannequin we expect that it’s appropriate for our drawback. We solely don’t know the A and B values/parameters proper now. In fact we will randomly strive few values for the parameters and see how good it matches to information however for a lot tougher issues it wouldn’t be attainable and we all the time want a scientific option to resolve the issues.
Though we can not strive random values we will begin with a random worth for the parameters. Let’s assume that A is 4 an B is 2 and calculate the distinction between the true y values and the values we predicted utilizing our components (y_hat).
f(x) = 4x + 2 = y_hat = [-18, -14, -14, -14, -14, -14, -10, -6, -2, -2, -2, 2, 2, 2, 2, 6, 6, 6, 14, 14]

It doesn’t look unhealthy however it’s clear that it isn’t the optimum answer. Now we have to strive different values for A and B parameters however how can we do this? Earlier than deciding the subsequent values, we first have to assess how good A = 4, B = 2 values for our drawback. To enhance one thing we want to have the ability to mesaure it. Therefore it’s time to determine a metric to calculate error. Let’s say we determined to make use of Imply Sq. Error(MSE) as a metric.

Utilizing MSE components our error is 43.8. Now the query is what we should always strive for A and B values? Let’s first take into account the A parameter. Ought to we improve it or lower it? Think about you might be on a mountain and also you wish to return to the bottom and also you don’t know the place you might be. However since you realize you’re on a mountain you realize that you need to go down. Our MSE components adjustments in accordance A and B parameters and it creates some mountains. Related in actual we don’t have to know what we’re precisely however the course we should always go. Due to gradient we will do this. We wish to decrease MSE so we should always want to search out its gradient. Let’s first begin with the A parameter.

You don’t actually perceive how we discovered the gradient for MSE. Let’s calculate the gradient for A=4 and see which course we should always go. You may calculate your self however the result’s 2.9 and since it’s a optimistic quantity (optimistic slop) and we wish to decrease meaning we have to lower the A parameter.

We don’t know the way a lot we should always lower so we will use magnitude of the gradient 2.9. Our new worth A = 4–2.9 = 1.1. Let’ calculate MSE worth for A=1.1 and B=2. Our MSE is 69.87 now. It was 43.8 earlier than and we discovered the next error. The rationale for that is known as overshooting. We discovered the proper course however we steped too giant so we missed the minimal level.

To beat the overshooting we will multiply the magnitude of gradient with a price between [0, 1]. That is additionally a paramter that we have to modify. Should you choose too small worth it takes a lot time to search out the optimum and in case you set it to too giant worth you may overshoot the optimum worth. This parameter additionally has a particular title known as “studying price”. Let’s replace our A price however use studying price as 0.5. A = 4–(0.5 * 2.9) = 2.55. Within the senario the place A=2.55 and B=2, MSE 41.9 and it’s decrease than earlier than.
Thus far I clarify the idea utilizing just one parameter however we typically we’ve got multiple parameters. We have to take gradient of every parameters and replace their values accordingly.

The issue with Gradient Descent/Ascent it isn’t gruanteed that you’re gonna discover the very best answer. There’s a probability that you simply would possibly discover native minimal/most level as a substitute of worldwide minimal/most level.
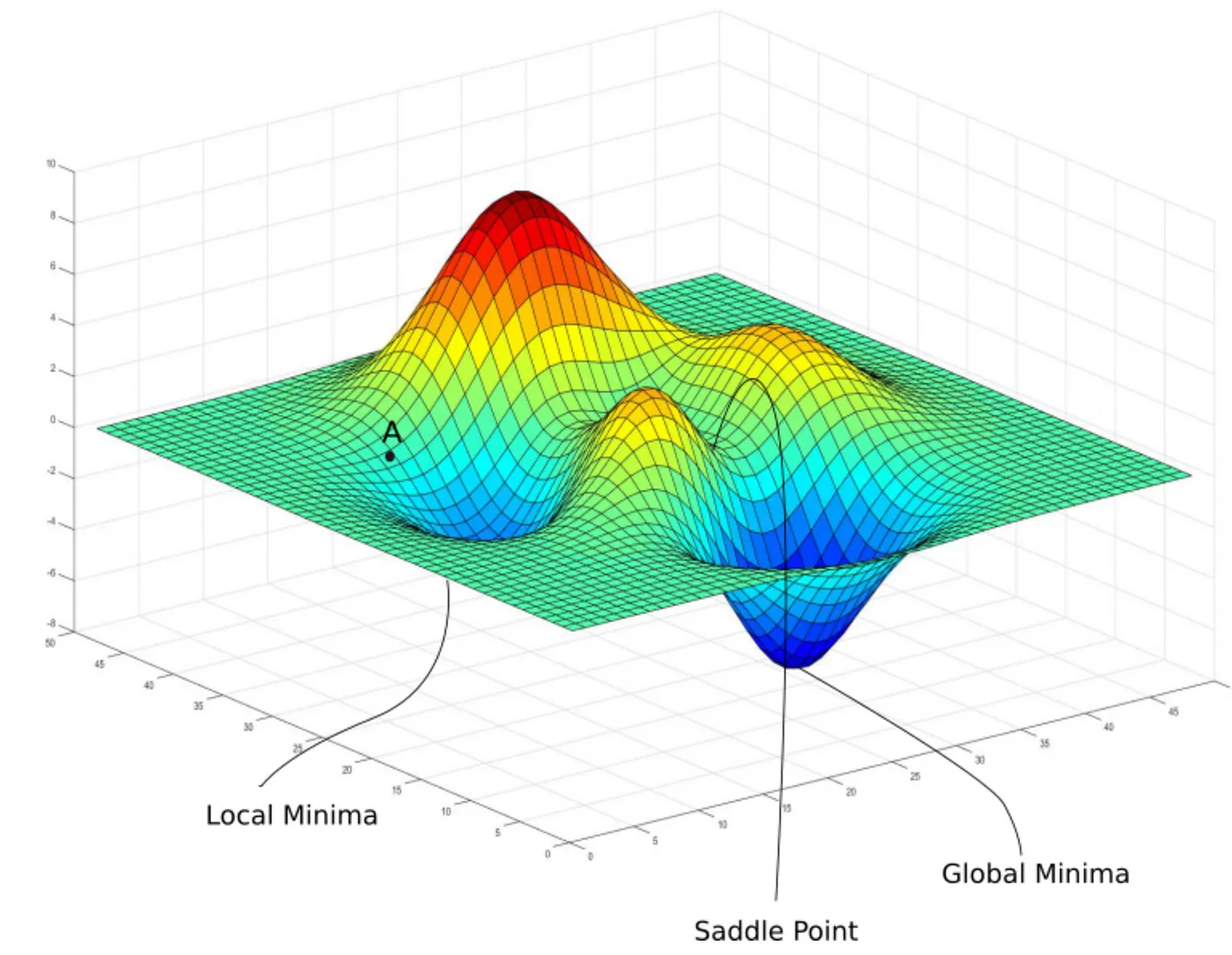
To unravel that drawback you can begin with totally different random values for paramters and optimize the parameters to ensure you discovered the worldwide minima or maxima.
The opposite query is when you could cease to updating the parameters? If the magnitude of the parameters are actually near zero you may cease updating the parameters or you may set a restricted time to search out the optimum values for parameters.
I’ve tried to elucidate the idea in a easy method however if you wish to be taught extra I counsel that you need to watch this YouTube video: https://youtu.be/RQAnrM_aV6s?list=PLU98PJIZ0JfIUmC2e8uShRgKiyLYM06Q4