
Introduction
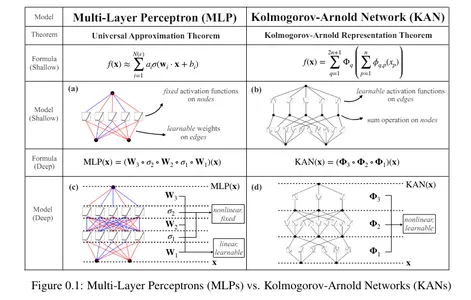
Kolmogorov-Arnold Networks, also called KAN, are the newest development in neural networks. Based mostly on the Kolgomorov-Arnold illustration theorem, they’ve the potential to be a viable different to Multilayer Perceptrons (MLP). In contrast to MLPs with fastened activation features at every node, KANs use learnable activation features on edges, changing linear weights with univariate features as parameterized splines.
A analysis group from the Massachusetts Institute of Know-how, California Institute of Know-how, Northeastern College, and The NSF Institute for Synthetic Intelligence and Elementary Interactions offered Kolmogorov-Arnold Networks (KANs) as a promising alternative for MLPs in a current paper titled “KAN: Kolmogorov-Arnold Networks.”
Studying Aims
- Be taught and perceive a brand new sort of neural community referred to as Kolmogorov-Arnold Community that may present accuracy and interpretability.
- Implement Kolmogorov-Arnold Networks utilizing Python libraries.
- Perceive the variations between Multi-Layer Perceptrons and Kolmogorov-Arnold Networks.
This text was printed as part of the Data Science Blogathon.
Kolmogorov-Arnold representation theorem
According to the Kolmogorov-Arnold representation theorem, any multivariate continuous function can be defined as:
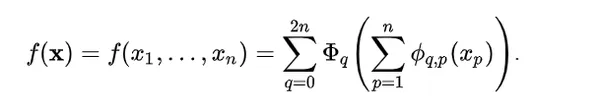
Here:
ϕqp : [0, 1] → R and Φq : R → R
Any multivariate function can be expressed as a sum of univariate functions and additions. This might make you think machine learning can become easier by learning high-dimensional functions through simple one-dimensional ones. However, since univariate functions can be non-smooth, this theorem was considered theoretical and impossible in practice. However, the researchers of KAN realized the potential of this theorem by expanding the function to greater than 2n+1 layers and for real-world, smooth functions.
What are Multi-layer Perceptrons?
These are the simplest forms of ANNs, the place info flows in a single course, from enter to output. The community structure doesn’t have cycles or loops. Multilayer perceptrons (MLP) are a kind of feedforward neural community.
Multilayer Perceptrons are a kind of feedforward neural community. Feedforward Neural Networks are easy synthetic neural networks wherein info strikes ahead, in a single course, from enter to output through a hidden layer.
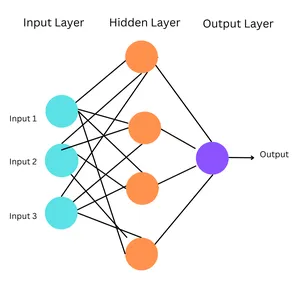
Working of MLPs
- Enter Layer: The enter layer consists of nodes representing the enter information’s options. Every node corresponds to 1 function.
- Hidden Layers: MLPs have a number of hidden layers between the enter and output layers. The hidden layers allow the community to be taught advanced patterns and relationships within the information.
- Output Layer: The output layer produces the ultimate predictions or classifications.
- Connections and Weights: Every connection between neurons in adjoining layers is related to a weight, figuring out its energy. Throughout coaching, these weights are adjusted by backpropagation, the place the community learns to attenuate the distinction between its predictions and the precise goal values.
- Activation Features: Every neuron (besides these within the enter layer) applies an activation operate to the weighted sum of its inputs. This introduces non-linearity into the community.
Simplified Components

Right here:
- σ = activation operate
- W = tunable weights that symbolize connection strengths
- x = enter
- B = bias
MLPs are primarily based on the common approximation theorem, which states {that a} feedforward neural community with a single hidden layer with a finite variety of neurons can approximate any steady operate on a compact subset so long as the operate shouldn’t be a polynomial. This enables neural networks, particularly these with hidden layers, to symbolize a variety of advanced features. Thus, MLPs are designed primarily based on this (with a number of hidden layers) to seize the intricate patterns in information. MLPs have fastened activation features on every node.
Nevertheless, MLPs have a number of drawbacks. MLPs in transformers make the most of the mannequin’s parameters, even these that aren’t associated to the embedding layers. They’re additionally much less interpretable. That is how KANs come into the image.
Kolmogorov-Arnold Networks (KANs)
A Kolmogorov-Arnold Community is a neural community with learnable activation features. At every node, the community learns the activation operate. In contrast to MLPs with fastened node activation features, KANs have learnable activation features on edges. They change the linear weights with parametrized splines.
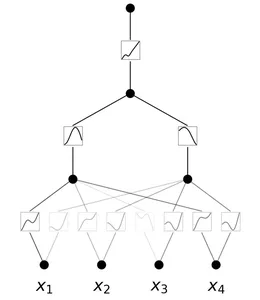
Benefits of KANs
Listed below are the benefits of KANs:
- Better Flexibility: KANs are extremely versatile attributable to their activation features and mannequin structure, thus permitting higher illustration of advanced information.
- Adaptable Activation Features: In contrast to in MLPs, the activation features in KANs aren’t fastened. Since their activation features are learnable on edges, they’ll adapt and regulate to completely different information patterns, thus successfully capturing numerous relationships.
- Higher Complexity Dealing with: They change the linear weights in MLPs by parametrized splines, thus they’ll deal with advanced, non-linear information.
- Superior Accuracy: KANs have demonstrated higher accuracy in dealing with high-dimensional information
- Extremely Interpretable: They reveal the buildings and topological relationships between the info thus they’ll simply be interpreted.
- Various Purposes: they’ll carry out varied duties like regression, partial differential equations fixing, and continuous studying.
Additionally learn: Multi-Layer Perceptrons: Notations and Trainable Parameters
Easy Implementation of KANs
Let’s implement KANs with the assistance of a easy instance. We’re going to create a customized dataset of the operate: f(x, y) = exp(cos(pi*x) + y^2). This operate takes two inputs, calculates the cosine of pi*x, provides the sq. of y to it, after which calculates the exponential of the consequence.
Necessities of Python library model:
- Python==3.9.7
- matplotlib==3.6.2
- numpy==1.24.4
- scikit_learn==1.1.3
- torch==2.2.2
!pip set up git+https://github.com/KindXiaoming/pykan.git
import torch
import numpy as np
##create a dataset
def create_dataset(f, n_var=2, n_samples=1000, split_ratio=0.8):
# Generate random enter information
X = torch.rand(n_samples, n_var)
# Compute the goal values
y = f(X)
# Cut up into coaching and check units
split_idx = int(n_samples * split_ratio)
train_input, test_input = X[:split_idx], X[split_idx:]
train_label, test_label = y[:split_idx], y[split_idx:]
return {
'train_input': train_input,
'train_label': train_label,
'test_input': test_input,
'test_label': test_label
}
# Outline the brand new operate f(x, y) = exp(cos(pi*x) + y^2)
f = lambda x: torch.exp(torch.cos(torch.pi*x[:, [0]]) + x[:, [1]]**2)
dataset = create_dataset(f, n_var=2)
print(dataset['train_input'].form, dataset['train_label'].form)
##output: torch.Dimension([800, 2]) torch.Dimension([800, 1])
from kan import *
# create a KAN: 2D inputs, 1D output, and 5 hidden neurons.
# cubic spline (ok=3), 5 grid intervals (grid=5).
mannequin = KAN(width=[2,5,1], grid=5, ok=3, seed=0)
# plot KAN at initialization
mannequin(dataset['train_input']);
mannequin.plot(beta=100)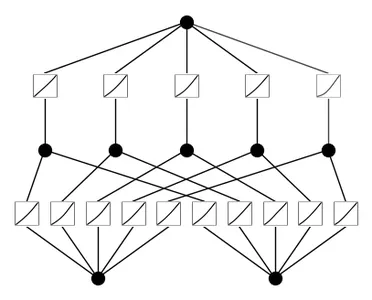
## practice the mannequin
mannequin.practice(dataset, choose="LBFGS", steps=20, lamb=0.01, lamb_entropy=10.)
## output: practice loss: 7.23e-02 | check loss: 8.59e-02
## output: | reg: 3.16e+01 : 100%|██| 20/20 [00:11<00:00, 1.69it/s]
mannequin.plot()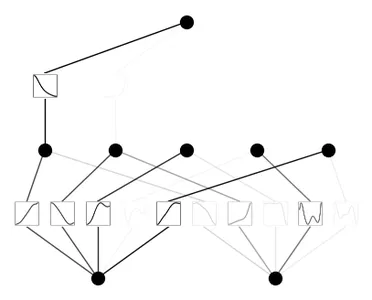
mannequin.prune()
mannequin.plot(masks=True)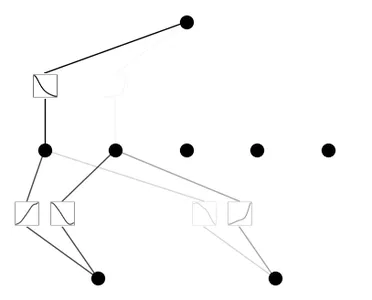
mannequin = mannequin.prune()
mannequin(dataset['train_input'])
mannequin.plot()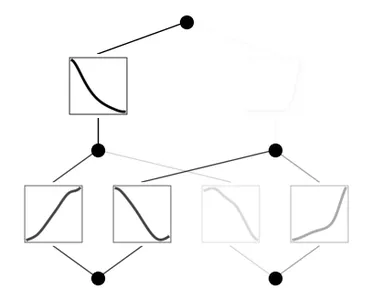
mannequin.practice(dataset, choose="LBFGS", steps=100)
mannequin.plot()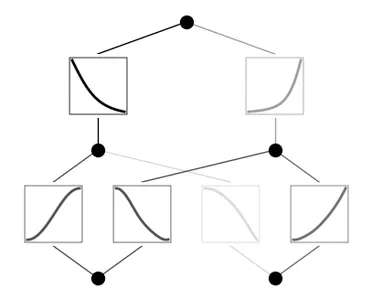
Code Clarification
- Set up the Pykan library from Git Hub.
- Import libraries.
- The create_dataset operate generates random enter information (X) and computes the goal values (y) utilizing the operate f. The dataset is then cut up into coaching and check units primarily based on the cut up ratio. The parameters of this operate are:
- f: operate to generate the goal values.
- n_var: variety of enter variables.
- n_samples: whole variety of samples
- split_ratio: ratio to separate the dataset into coaching and check units, and it returns a dictionary containing coaching and check inputs and labels.
- Create a operate of the shape: f(x, y) = exp(cos(pi*x) + y^2)
- Name the operate create_dataset to create a dataset utilizing the beforehand outlined operate f with 2 enter variables.
- Print the form of coaching inputs and their labels.
- Initialize a KAN mannequin with 2-dimensional inputs, 1-dimensional output, 5 hidden neurons, cubic spline (ok=3), and 5 grid intervals (grid=5)
- Plot the KAN mannequin at initialization.
- Prepare the KAN mannequin utilizing the supplied dataset for 20 steps utilizing the LBFGS optimizer.
- After coaching, plot the skilled mannequin.
- Prune the mannequin and plot the pruned mannequin with the masked neurons.
- Prune the mannequin once more, consider it on the coaching enter, and plot the pruned mannequin.
- Re-train the pruned mannequin for an extra 100 steps.
MLP vs KAN
| MLP | KAN |
| Fastened node activation features | Learnable activation features |
| Linear weights | Parametrized splines |
| Much less interpretable | Extra interpretable |
| Much less versatile and adaptable as in comparison with KANs | Extremely versatile and adaptable |
| Sooner coaching time | Slower coaching time |
| Based mostly on Common Approximation Theorem | Based mostly on Kolmogorov-Arnold Illustration Theorem |
Conclusion
The invention of KANs signifies a step in direction of advancing deep studying strategies. By offering higher interpretability and accuracy than MLPs, they could be a more sensible choice when interpretability and accuracy of the outcomes are the primary goal. Nevertheless, MLPs could be a extra sensible resolution for duties the place pace is important. Analysis is constantly occurring to enhance these networks, but for now, KANs symbolize an thrilling different to MLPs.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Writer’s discretion.
Frequently Asked Questions
A. Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljaci, Thomas Y. Hou, Max Tegmark are the researchers involved in the dQevelopment of KANs.
A. Fixed activation functions are mathematical functions applied to the outputs of neurons in neural networks. These functions remain constant throughout training and are not updated or adjusted based on the network’s learning. Ex: Sigmoid, tanh, ReLU.
Learnable activation functions are adaptive and modified during the training process. Instead of being predefined, they are updated through backpropagation, allowing the network to learn the most suitable activation functions.
A. One limitation of KANs is their slower training time due to their complex architecture. They require more computations during the training process since they replace the linear weights with spline-based functions that require additional computations to learn and optimize.
A. If your task requires more accuracy and interpretability and training time isn’t limited, you can proceed with KANs. If training time is critical, MLPs are a practical option.
A. The LBFGS optimizer stands for “Limited-memory Broyden–Fletcher–Goldfarb–Shanno” optimizer. It is a popular algorithm for parameter estimation in machine learning and numerical optimization.